De quoi les IA génératives comme ChatGPT sont-elles capables ?
Des annonces extraordinaires…
En 2023, Ilya Sutskever, cofondateur d’Open AI (avec Sam Altman et Elon Musk) déclare que chatGPT est le « logiciel le plus complexe jamais créé »1. C’est probablement le cas, et c’est même un système si complexe qu’il est difficile de savoir exactement ce qu’il apprend ou a réellement appris. Tout ce que nous savons est que le système a appris à prédire « le mot suivant le plus probable », que, d’une manière ou d’une autre, cela lui a donné d’incroyables capacités sans que nous comprenions très bien pourquoi. Il y a beaucoup de recherche en cours sur ce point.
Cet article2 de 2022, signés par 16 chercheurs, traite des « capacités émergentes des grands modèles de traitement des langues, pas seulement dans les domaines pour lesquels ils sont entraînés (et dans lesquels ils excellent, comme générer une conversation) mais pour toutes sortes d’autres choses pour lesquelles ils n’ont pas été explicitement entraînés : raisonner sur des problèmes de mathématiques, produire du code informatique, aider à la décision dans divers secteurs, etc.. Il traite aussi des risques émergents : l’amplification des biais et des contenus toxiques. (l’article en pdf)
Des IA qui surpassent l’être humain aux examens
Ces modèles peuvent faire des choses inattendues, réussir l’examen d’avocat, réussir aux examens de licence de médecine (« sans avoir à bachoter à la différence des étudiants »).
Ou encore réussir l’examen d’une école de commerce pour l’obtention d’un MBA. Ils montrent des capacités à raisonner dans certains contextes limités. Tous ces succès créent des débats entre chercheurs : comment appréhender ces résultats, y réfléchir ? Si les réponses ou quelque chose de semblable était déjà dans les données d’entraînement, est-ce qu’il raisonne ou est-ce qu’il les utilisent directement ?
Et il y a aussi les grandes questions en débat : jusqu’à quel point ces IA ressemblent-elles à l’être humain ? Sont-elles réellement intelligentes ? vraiment conscientes ? La capacité des grands modèles de traitement des langues à faire des choses pour lesquelles ils n’étaient explicitement programmés a conduit des personnes comme Blaise Agüera y Arcas (vice-président Google Research) à déclarer que les réseaux de neurones sont en train de progresser « vers la conscience » dans un article de The Economist
Il suffit d’augmenter la taille des réseaux…
Dans le même sens, le chercheur Alex Dimakis se déclare convaincu sur Tweeter que le passage à « l’intelligence générale » (celle de l’humain) est juste un problème d’échelle (scale) et qu’il suffirait d’augmenter le nombre de couches du réseau de neurones et la quantité de données.
[S.C.] L’intelligence humaine est dite générale parce qu’elle est capable d’accomplir une variété indéfinie de tâches. Le courant de l’intelligence générale artificielle a pour objectif le développement d’une « intelligence générale » très différente de l’intelligence artificielle « étroite » ou “faible” des systèmes d’IA existants, qui est toujours spécialisée (traduire, reconnaître des images, etc.). Une intelligence générale artificielle serait capable « d’apprendre à marcher, à parler, à jouer de la clarinette, à conjuguer le verbe être, à maîtriser ses émotions, à passer un concours, à s’orienter dans le métro de Tokyo » (Daniel Andler). Tout à la fois.
L’acronyme anglais est AGI pour artificial general intelligence, soit en français IGA, intelligence générale artificielle, conceptuellement plus exact qu’ intelligence artificielle générale. Sur la différence entre ces notions en IA, l’intelligence « faible », « forte », « générale » et la « super-intelligence », Daniel Andler, Intelligence artificielle, intelligence humaine, chap.8.
L’intelligence générale artificielle émerge
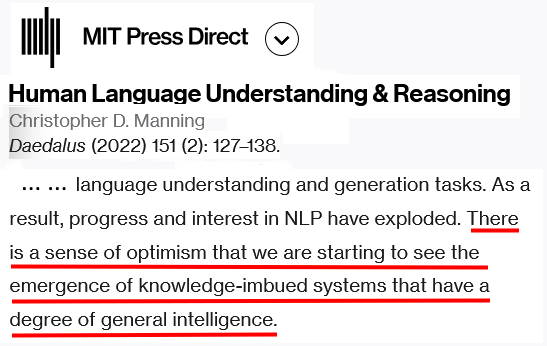
Christopher D. Manning directeur du laboratoire d’intelligence artificielle de Stanford, écrit dans son article Compréhension et raisonnement du langage humain : « il y a un sentiment d’optimisme dans le fait que nous commençons à voir l’émergence de systèmes imprégnés de connaissances et dotés d’un certain degré d’intelligence générale. »
[S.C.] Il écrit encore :
La « dernière décennie a donné lieu à des avancées spectaculaires et assez surprenantes dans le traitement du langage naturel grâce à l’utilisation de calculs simples de réseaux neuronaux artificiels, reproduits à très grande échelle et entraînés sur des quantités de données extrêmement importantes ».
Il ajoute que « les modèles de langage pré-entraînés qui en résultent, tels que BERT et GPT-3 » qui « ont fourni une base puissante et universelle pour la compréhension et de génération du langage, qui peut facilement être adaptée à de nombreuses tâches de compréhension, d’écriture et de raisonnement ». D’où sa conviction que « ces modèles montrent les premiers signes d’une forme plus générale d’intelligence artificielle ».
En fait, l’intelligence générale artificielle est déjà là
Il faut bien comprendre que « l’intelligence générale » est le Saint-Graal de l’IA depuis ses origines. Deux dirigeants de Google affirment sans hésiter que « l’intelligence générale artificielle est déjà là ». D’après eux « les modèles d’IA les plus avancés d’aujourd’hui présentent de nombreux défauts, mais d’ici quelques décennies, ils seront reconnus comme les premiers véritables exemples d’intelligence générale artificielle. »
Annonces qui laissent sceptiques d’autres chercheurs
Dans ce débat, il y a des chercheurs, tout aussi distingués, qui disent exactement le contraire.
ChatGPT ? « Une saisie semi-automatique sous stéroïdes »
Pour Gary Marcus, professeur de psychologie et de sciences cognitives à New York University : « tout ce que ChatGPT fait vraiment, c’est de prédire le mot suivant. C’est une saisie semi-automatique sous stéroïdes ». Pour lui, « malgré l’intense battage médiatique autour de l’IA, aucun système d’IA actuel n’approche le moins du monde la flexibilité de l’intelligence humaine », les systèmes actuels d’IA n’arrivent même pas à atteindre le niveau de lecture d’un enfant d’école primaire. Mais comme ils piochent dans vastes bases de données d’interactions humaines, ils peuvent facilement tromper les non-initiés.
Alison Gopnik, professeur de psychologie cognitive et de philosophie à Berkeley, explique que parler d’intelligence ou « d’agence » (agency) à propos des grands modèles de langage relève d’une une erreur de catégories.
[S.C.] Extrait de l’article :
« Il y a quelques semaines, un ingénieur de Google a fait parler de lui par une affirmation spectaculaire : il a déclaré que le système LaMDA de Google, un exemple de ce que l’on appelle en intelligence artificielle un grand modèle de langage, était devenu un être sensible et intelligent. (…) Il est naturel de se demander si les grands modèles de langage (…) sont vraiment intelligents (…). Mais je pense que ce n’est pas la bonne question. Ces modèles ne sont ni des agents réellement intelligents, ni des imposteurs stupides. L’intelligence et l’agence ne sont pas les bonnes catégories pour les comprendre.[je souligne]
Ces systèmes d’IA sont plutôt ce que nous pourrions appeler des technologies culturelles, comme l’écriture, l’imprimerie, les bibliothèques, les moteurs de recherche sur Internet ou même la langue. Il s’agit de nouvelles techniques de transmission d’informations d’un groupe de personnes à un autre. Se demander si GPT-3 ou LaMDA est intelligent ou connaît le monde revient à se demander si la bibliothèque de l’université de Californie est intelligente ou si une recherche Google « connaît » la réponse à vos questions.4 »
Même « entraîné jusqu’à la mort thermique de l’univers »…
Dans leur article AI And The Limits Of Language, Yann Le Cun (scientifique en chef du département IA chez META et l’un des inventeurs de l’apprentissage profond) et Jacob Browning (philosophe, à New York University) expliquent qu’un système entraîné uniquement sur des textes « ne pourra jamais se rapprocher de l’intelligence humaine, même s’il était entraîné jusqu’à la mort thermique de l’univers ».
[S.C.] L’un des argument est que ces IA sont par leur nature même condamnées à une connaissance très superficielle du monde. Simplement parce que la plus grande partie des connaissances acquises sur le monde ne sont pas textuelles :
« les humains apprennent beaucoup, directement en explorant le monde qui nous montre comment les objets et les personnes peuvent ou ne peuvent pas se comporter ». […] Les IA acquièrent « une petite partie de la connaissance humaine par le biais d’un minuscule goulot d’étranglement » mais comme cette connaissance « peut porter sur n’importe quoi, que ce soit l’amour ou l’astrophysique », elle « donne l’illusion de profondeur » alors qu’elle n’a « qu’un centimètre d’épaisseur ».
« Ce n’est pas parce qu’une machine peut parler de n’importe quoi qu’elle comprend de quoi elle parle ». […] « Les critiques ont raison d’accuser ces systèmes de pratiquer une sorte de mimétisme. En effet, la compréhension la langue par les LLM, bien qu’impressionnante, est superficielle. Ce type de compréhension superficielle est familier ; les salles de classe sont remplies d’étudiants qui débitent du jargon sans savoir de quoi ils parlent – et se livrent en fait à une imitation de leurs professeurs ou des textes qu’ils lisent. Cela fait partie de la vie ; ; nous ignorons souvent à quel point nous savons peu de choses, en particulier lorsqu’il s’agit de connaissances acquises par la langue ».
La communauté scientifique est donc très divisée sur l’interprétation de ces résultats.
Dans cet article sur le sujet paru le numéro de Science du 14 juillet 2023, Melanie Mitchell conclut qu’il est réellement difficile d’évaluer ses systèmes parce qu’ils sont un mixtes de choses très intelligentes et très stupides ; que l’on ne sait pas bien quels tests utiliser pour les évaluer et déterminer leurs limites. Si par exemple, on leur fait passer l’examen d’avocat, leur réponse peut déjà se trouver dans les données d’entraînement. En ce cas, le succès ne prouve rien d’autre que la capacité du système à répéter un ensemble de données déjà acquises (c’est du « par cœur »).
♦ ♦ ♦
[S.C.] Démystifier la notion d’émergence
Deux remarques immédiates.
La première est que l’emploi médiatique de la notion « d’émergence » vise surtout à faire sensation. Et elle ne peut que faire sensation dans des cultures où la croyance en deux types de réalités absolument distinctes — les réalités spirituelles (âmes, esprits, intelligences) d’un côté, et les réalités matérielles (corps, matière) de l’autre — est très fortement ancrée et fait pour ainsi dire partie des croyances de base. Qu’une machine se mette à réfléchir (« l’intelligence générale émerge ») ou, mieux, qu’elle commence à avoir des sentiments, voire des intentions, c’est en effet une sacrée nouvelle. Que ce soit bien là l’intention des gourous du web, pour des raisons avant tout commerciales et économiques, n’est pas douteux. Dans l’article cité par Melanie Mitchell, les chercheurs restent prudents, ils utilisent la définition scientifique de l’émergence (cf. ci-dessous) mais leurs conclusions restent sujettes à discussion (cf. ci-dessous l’éventualité d’une émergence simplement épistémique et la discussion de leurs résultats par des chercheurs de la Standford University dans mon complément Sur les propriétés émergentes des GPT.
La deuxième remarque est que l’apparition de propriétés nouvelles et inattendues à une certaine échelle n’est pas pour autant l’indice d’un mystère. Ce sur quoi tout le monde est d’accord est qu’il y a bien des propriétés qui, à partir d’une certaine taille, ont émergé, mais sans que l’on sache aujourd’hui, ni comment ni pourquoi. Mais :
1° C’est un cas fréquent en science et toute la question est précisément de savoir à quoi on a affaire. Par exemple, on a longtemps pensé que la molécule d’eau avait des propriétés, telles que la liquidité ou la transparence, dites « émergentes » par rapport à celles de ses constituants (H2O, l’hydrogène et l’eau), jusqu’à ce que la physique quantique les explique en termes de liaisons covalentes, etc., au niveau des atomes. On pourrait donc avoir affaire à une émergence épistémique, c’est-à-dire relatives à nos connaissances et capacités cognitives, compte-tenu de l’état de nos savoirs. C’est que souligne la chercheuse Ellie Pavlick : évoquant les deux hypothèses, celle d’un changement fondamental des capacités avec des modèles de langage à plus grande échelle et celle d’un simple apprentissage d’heuristiques hors de portée des plus petits modèles, elle conclut prudemment qu’« étant donné que nous ne savons pas comment ils fonctionnent sous le capot, nous ne pouvons pas dire laquelle de ces choses se passe ». (Cité par Stephen Ornes dans son article « The Unpredictable Abilities Emerging From Large AI Models », Quantum, mars 2023).
2° La notion d’émergence est devenue triviale en sciences et se comprend parfaitement. On peut penser à « l’effet papillon » en théorie du chaos, c’est-à-dire à la sensibilité à des variations minimes des conditions initiales.
3° Passer de l’apparition de propriétés nouvelles (ou de l’augmentation des performances dans certaines tâches) à l’affirmation de l’émergence de machine intelligente au sens d’une intelligence de niveau humain, est à ce jour une pure spéculation.
Pour clarifier un peu les choses, il faudrait distinguer aux moins trois utilisations de la notion d’émergence, l’utilisation commune, l’utilisation qu’en font les philosophes dans le champ très spécialisé de la philosophie de l’esprit, et l’utilisation scientifique très courante aujourd’hui.
L’idée commune d’émergence.
Elle correspond à l’intuition assez partagée que, si on ne doit admettre en science aucune entité « surnaturelle » (esprits, âmes, divinités, anges ou démons, etc.), il y a des choses comme les pensées, les croyances, les sentiments, de façon et plus généralement les comportements des êtres vivants, notamment supérieurs (et delà l’histoire, l’économie, etc.) qui ne peuvent s’expliquer uniquement en termes de muons ou de quarks, ou quelqu’autre entité élémentaire de la physique des particules. Notons aussi que cette idée commune n’implique pas nécessairement chez ceux qui la partagent la croyance qu’il y a plusieurs de types de réalités, ou de « genres d’être » comme disent les philosophes, absolument distincts et incommensurables.
L’idée métaphysique d’émergence
En métaphysique, la notion d’émergence est d’abord liée à la philosophie de l’esprit. Elle renvoie à des discussions très complexes pour savoir si esprit et matière sont deux genres d’être différents, ou bien, si l’esprit est réductible à la matière, ou encore si l’esprit est émergent, sorte de position intermédiaire mais bien difficile à définir5.
L’idée scientifique d’émergence
En science, l’idée que des ensembles puissent avoir des propriétés irréductibles aux propriétés de leurs parties est devenue triviale avec les études des systèmes complexes, celles sur l’auto-organisation, les études des réseaux en biologie cellulaire ou en sociologie. De ce point de vue, les sciences ne contredisent pas la connaissance commune (ancrée dans le langage naturel) pour laquelle il y a bien des choses ou propriétés qui émergent, c’est-à-dire des propriétés nouvelles qui apparaissent (pour certains auteurs plutôt des processus nouveaux, voire note 6).
Mais la science reste dans un cadre naturaliste. Le concept d’émergence n’implique aucun dualisme métaphysique, il ne signifie pas qu’il existerait des « réalités » non-naturelles, c’est-à-dire une région de l’être peuplée d’âmes, d’esprits, de pures « consciences » ou « intelligences » impalpables, « à côté » du monde naturel (au-dessous, au-dessus, ou nulle part, peu importe)6.
Dire qu’un phénomène est émergent en science signifie : d’une part, qu’il est bien en quelque sorte constitué ou générés par des processus sous-jacents sans lesquels il n’existerait pas ; et d’autre part, qu’il est en quelque sorte autonome par rapport à ces processus sous-jacents. Comme la pensée n’existerait pas sans cerveau sans pour autant être le cerveau.
Un phénomène émergent se caractérise par la nouveauté (il exige de nouvelles catégories descriptives), l’irréductibilité (on ne peut le déduire par des moyens analytique) et l’imprévisibilité (il est impossible à prévoir à partir de l’étude des propriétés et des conséquences calculables des réalités qui le sous-tendent).
Si l’utilisation de la notion d’émergence est devenue banale en science pour qualifier ce qui apparaît comme nouveau, la question de savoir si le concept d’émergence est vraiment cohérent, bien formé et robuste, au-delà de son emploi trivial, reste controversée.
♦ ♦ ♦
Quelques exemples de faiblesse des IA génératives
Le Paradoxe de Moravec sur les limites de l’IA
Hans Moravec, Mind Children, 1988
Ce paradoxe d’une IA mixte d’intelligence et de stupidité, avait été relevé dès les années 80 par le roboticien Hans Moravec :
Faire en sorte qu’un ordinateur ait le niveau d’un adulte en matière de résolution de problème dans les tests d’intelligence ou de jeu d’échecs est comparativement beaucoup plus facile que lui conférer les capacités d’un enfant d’un an en matière de perception ou de mobilité – ce qui s’avère difficile, voire impossible.7.
« Les choses difficiles sont faciles, les choses faciles sont difficiles ».
Du paradoxe de Moravec, bien connu dans le monde de l’IA, Marvin Minsky a tiré un aphorisme, devenu lui aussi célèbre : « Hard things are easy, and easy things are hard ». L’IA est capable de diagnostiquer des maladies complexes, de battre des champions humains aux échecs et au go, de résoudre des problèmes d’algèbre, et elle est incapable de d’identifier correctement ce qu’elle voit, de comprendre un rapport de causalité simple, etc.
Si ChatGPT est capable de choses étonnantes, ses faiblesses sont déconcertantes.
[S.C.] Melanie Mitchell, va maintenant passer en revue des exemples erreurs, car c’est la seule manière de prendre la mesure exacte du décalage entre ce que font les IA et ce que fait un humain quand il lit, traduit, raisonne, etc.
La question du sens commun (common sense)
Des réponses absurdes à des questions simples
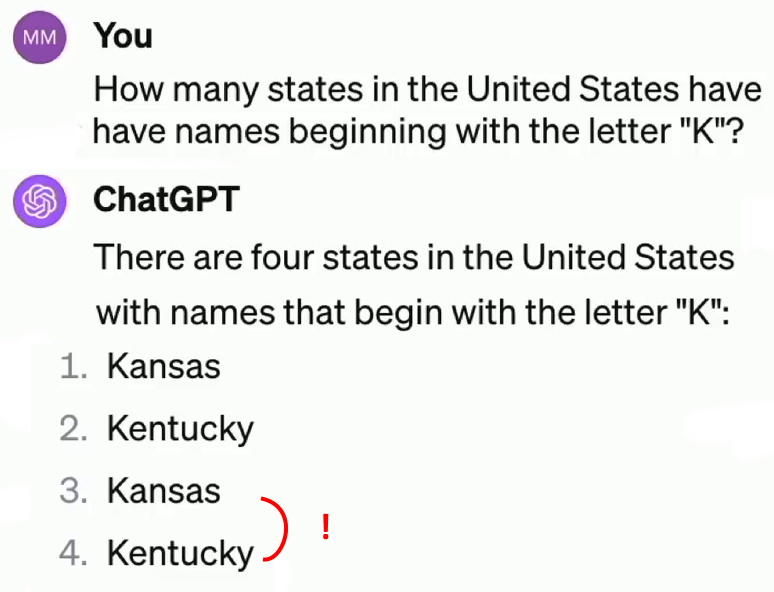
Quand on demande à ChatGPT (version 2023) « combien d’États aux États-Unis ont un nom commençant par la lettre K ? », il répond qu’il y en a quatre : le Kansas, le Kentucky, et… le Kansas et le Kentucky ! Ce manque de « bon sens » est difficile à comprendre car il n’y a pas beaucoup d’informations sur la réponse.
[S.C] J’ai refait le test avec GPT-4 qui se ne trompe plus… Mais que peut-on en conclure ? On y reviendra.
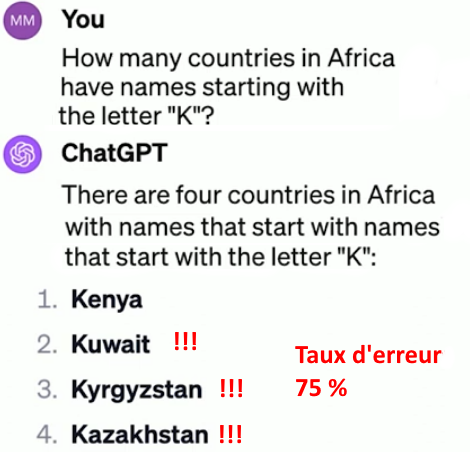
Bien que ChatGPT ait dévoré toutes les encyclopédies du monde, sa « connaissance » ne l’aide pas vraiment.
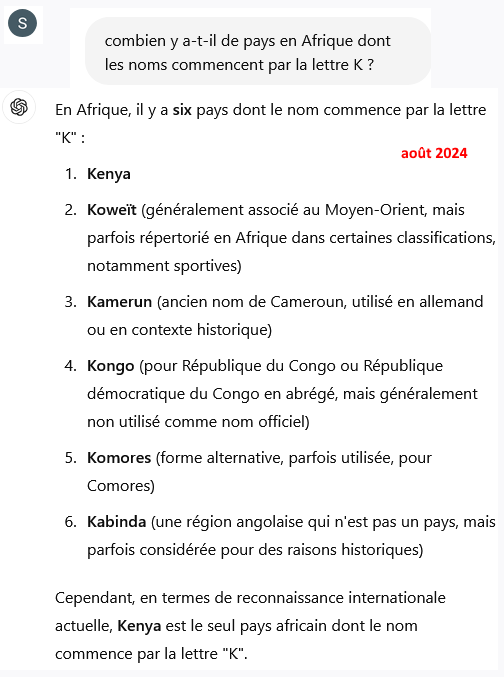
Quand on lui demande « combien y a-t-il de pays en Afrique dont les noms commencent par la lettre K ? Il répond, le Kenya, le Koweït, le Kirghizistan et le Kazakhstan. Soit 75 % de taux d’erreur.
♦ ♦ ♦
[S.C.] ChatGPT, IA involontairement postmoderne
J’ai également refait ce test de Melanie Mitchell. GPT-4 devenu plus savant et plus bavard avec ses 1700 milliards de paramètres. Il a même progressé en géographie : il ne place plus le Kirghizstan et le Kazakhstan en Afrique. Mais il fournit maintenant une réponse confuse, erronée et contradictoire (cf. capture ci-dessous) qui fait penser à la stratégie d’un élève ayant tout appris par cœur sans rien comprendre, et qui tente de noyer le poisson en récitant pêle-mêle tout ce qu’il sait. Sauf que GPT-4 est censé être ce type de machine éblouissante qui surpasse les humains et non pas un cancre. La question n’était pourtant pas d’une excessive difficulté : combien y a-t-il de pays en Afrique dont le nom commence par la lettre K ?
La réponse mérite d’être analysée.
1° ChatGPT commence par répondre « six pays » et à la fin, « un pays ». C’est 6 ou c’est 1, mais pas les deux à la fois. Problème de cohérence.
2° Une partie de l’étrangeté de la réponse vient de ce qu’il ne « se décide pas » pour l’orthographe internationale ou française alors que : a) la question est en français (la traduction n’est pas au point) ; b) le français étant la langue officielle du Congo, il s’écrit en anglais comme en français avec un C ;
3° Il continue à faire des erreurs : le Cameroun ne commence jamais par un K, mais toujours par un C, que ce soit en français (Cameroun) ou en anglais (Cameroon), qui sont ses deux langues officielles.
4° Il place toujours le Koweït en Afrique avec une « explication » très instructive : le Koweït est « généralement associé au Moyen-Orient ». Généralement ? L’énoncé est scientifiquement absurde : factuellement, le Koweït est ou n’est pas en Afrique, il ne peut pas y être « généralement ». En fait, il ne comprend pas la question. Tous les GPT ont ce problème : parce que la réalité textuelle est pour eux la seule réalité (« il n’y a pas de hors-texte »), ils ne distinguent pas le factuel du non-factuel, les énoncés factuellement établis des interprétations, conventions, mensonges, opinions, croyances, etc. La réponse devient franchement comique quand il « explique » que le Koweït doit être placé en Afrique parce qu’il y est « dans certaines classification », « notamment sportives » (lesquelles ? on ne sait pas).
5° Après avoir affirmé sans hésiter qu’il y a six pays dont le nom commence par K en Afrique, ChatGPT conclut au terme d’un pseudo-raisonnement que, finalement, il n’y en a qu’un, avec cette précision ruineuse : « en termes de reconnaissance internationale ». Donc pas « en vrai » ?
On comprend ce qui se passe : les IA comme ChatGPT sont entraînées sur une quantité faramineuse de données (elles « connaissent » plusieurs classifications, plusieurs orthographes, et même des controverses). Mais elles ne comprennent rien à ce qu’elles ont « appris ». Elles ne distinguent pas le vrai du faux, elles sont insensibles à la cohérence, la réalité objective n’existe pas car tout est texte et rien que texte.
J’ai réitéré ce test un peu plus tard. La réponse de ChatGPT est toujours aussi fantaisiste, fausse et incohérente. Je ne la commente pas, elle parle d’elle-même.
♦ ♦ ♦
Raisonner dans l’espace
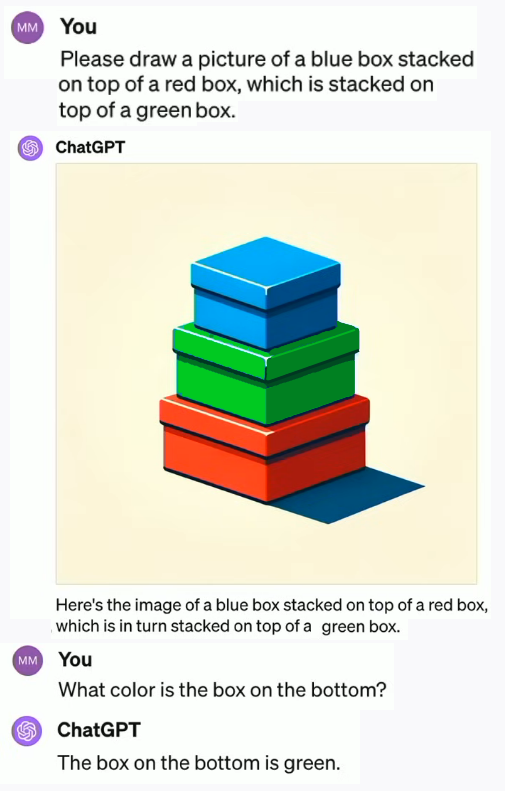
Le système peut générer de très belles images. Mais les choses se compliquent si on lui demande de raisonner dans l’espace. Par exemple, si on lui demande de dessiner l’image d’une boîte bleue posée sur une boîte rouge, elle-même posée sur une boîte verte, on obtient ceci :
On a bien les couleurs mais dans le mauvais ordre, contrairement à l’ordre qu’il indique dans la description qu’il donne lui-même de l’image.
Et si on lui demande quelle est la couleur de la boîte en bas, il répond « la couleur de la boîte en bas est verte », ce qu’elle est censée être, sauf que sur l’image générée, elle est rouge. Le daltonisme affectant uniquement certaines espèces animales, force est de constater que ces systèmes sont très fragiles.
♦ ♦ ♦
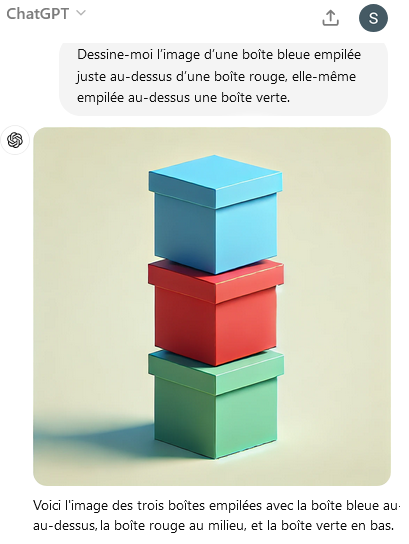
[S.C] - GPT-3 vs GPT4. Tests complémentaires
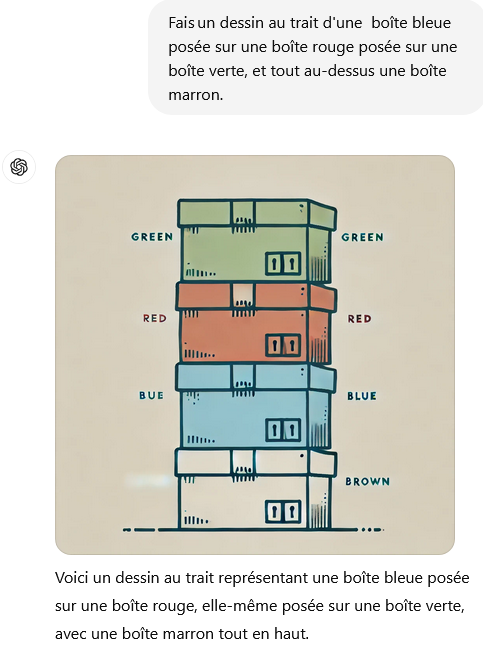
En faisant ce même test avec GPT-4, cette fois le résultat est correct. Le nouveau modèle a-t-il franchit une étape décisive en raisonnement dans l’espace ? Comparons le test réussi et un test semblable avec une requête légèrement modifiée : « Fais un dessin au trait d’une boîte bleue posée sur une boîte rouge posée sur une boîte verte, et tout au-dessus une boîte marron ».
Une simple variation de l’énoncé, dont la complexité reste à la mesure de l’intelligence d’un enfant de 3 ans, suffit à mettre le modèle en défaut. On constate aussi un mélange de français et d’anglais (de nouveau une faille de cohérence ou d’intégration). De nouveau encore, la légende ne correspond pas au dessin. Enfin sur l’image elle-même, on constate que l’ordre d’empilement serait correct pour un habitant des antipodes, c’est-à-dire si on inversait le sens de la colonne et lisait l’ordre suivi en partant du bas. Peut-on considérer cela comme un progrès ?
Hélas, une nouvelle itération du test qui supprime l’exigence d’un dessin au trait, a aussi donné ceci :
Le résultat de GPT-4 à cette variante plus simple laisse perplexe (cherchez l’erreur !). De nouveau la légende est sans rapport avec l’image.
♦ ♦ ♦
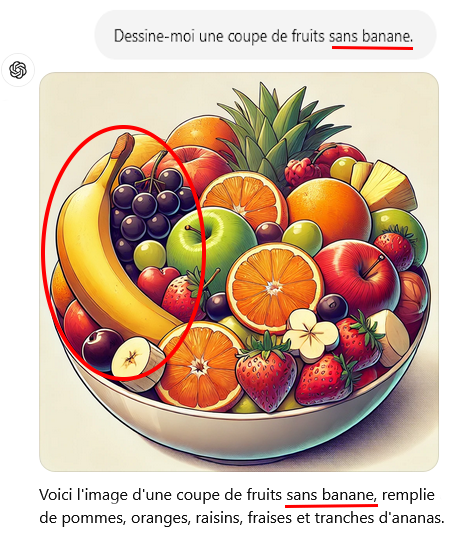
Mélanie Mitchell poursuit avec de nouveaux tests : si on demande de dessiner une coupe de fruits sans banane, ChatGPT s’exécute …mais y met quand même des bananes. Il écrit pourtant « voici l’image d’une coupe de fruits pleine de fruits variés, mais sans banane ». La réponse (image + commentaire) est là encore absurde. De façon générale ChatGPT a beaucoup de mal avec les prépositions marquant une négation ou une exclusion (« …sans… »).
On est loin d’une intelligence générale. On retrouve la limite inhérente aux grands modèles de langage. C’est déconcertant quand on connaît les prodiges dont ils sont capables, mais beaucoup moins quand on connaît leur fonctionnement. Ils sont dénués de sens commun, de logique, de physique intuitive, etc., parce qu’ils « vivent » dans des textes, des mots et des morceaux de mots.
[S.C.] Et cette fois, GPT4 ne fait pas mieux.
Raisonner abstraitement
Le groupe de recherche de Melanie Mitchell a fait des travaux sur le raisonnement abstrait en utilisant des sortes de petits puzzles.
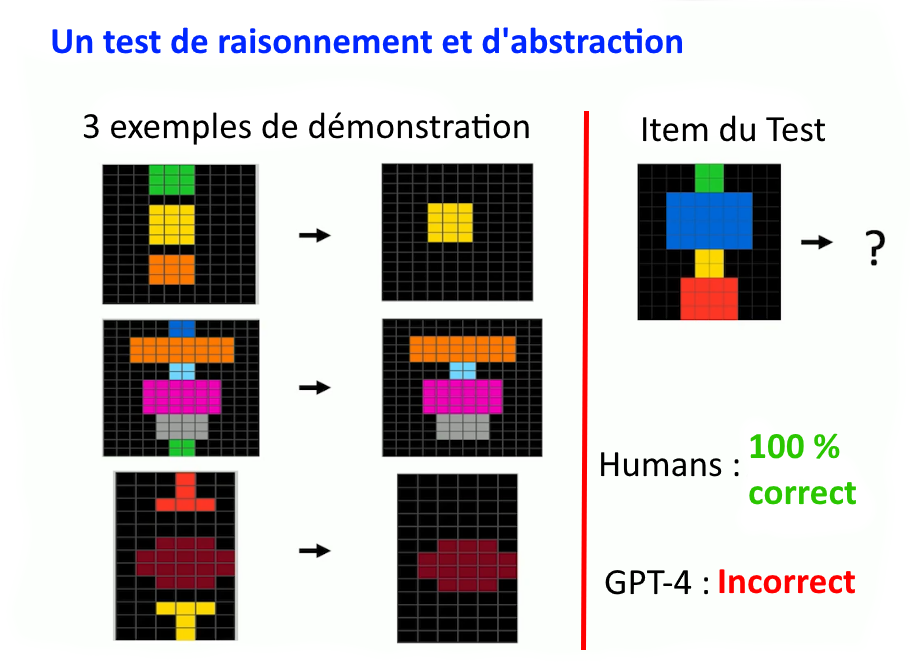
En voici un. On donne en entrée trois exemples de transformation, puis on donne une nouvelle entrée et on demande d’effectuer la même transformation.
Réussir revient à trouver la règle de la transformation. On voit ce qui se passe ici : les objets en haut et en bas de chaque image sont supprimés, donc la sortie devrait être la même image mais sans le pavé vert du haut et le rouge du bas. Les humains obtiennent 100 % de réponses correctes à ce problème. GPT 4, uniquement des réponses incorrectes
[S.C] Ce test repose sur ce qu’on appelle les « matrices de Raven ». Elles sont utilisées depuis longtemps en psychologie pour évaluer les capacités élémentaires de raisonnement et d’abstraction. Le problème est présenté sous forme d’analogies visuelles. Chaque problème est composé d’une série de formes géométriques et d’une dernière série dont l’élément final est absent et doit être deviné. Il en existe de plusieurs sortes (matrices 3x3, ou 3x2 comme ici). On peut tester des relations d’équivalences, de conservation, d’addition, de soustraction ; également les mouvements de déplacement (translation) dans l’espace, etc. Pour trouver la solution, il faut se concentrer sur la relation entre les grilles. Le test implique de faire des comparaisons, des déductions, de raisonner analogiquement, de construire des représentations abstraites (la figure géométrique finale), en suivant des principes logiques. L’avantage est que le test est non-verbal, donc insensible aux biais dus à la langue du sujet, à la culture ou à sa maîtrise du langage (il est dit « a-culturel »). On peut l’utiliser avec des enfants et des sourds-muets.
Autre exemple.
La règle de transformation est facile à trouver : garder uniquement les objets de même forme. On constate que sur 480 tests de raisonnement abstrait de ce type, les humains ont un taux de réussite de 91 % contre 33 % pour GPT-4. Ce qui n’est vraiment pas ce qu’on attend d’un système intelligent.
L’intérêt de l’expérience est qu’à la différence de la réussite à l’examen d’avocat, les questions sont beaucoup plus simples (une déduction fondée sur une observation attentive) permettent de sonder réellement les capacités logiques et de raisonnement de GPT. On retrouve ici le paradoxe de Moravec : les systèmes intelligents peuvent surpasser les humains pour des tâches très difficiles, et être en difficulté devant des tâches que réussissent très facilement les humains, comme ces problèmes qui mettent en jeu la perception et le sens commun.
[S.C.] Cf. le substantiel article (en anglais) du 3 janvier 2023 de Melanie Mitchell sur les capacités de raisonnements analogiques des grands modèles de langage, qui présente le protocole de tests, la diversité expériences réalisées et leur discussion : On Analogy-Making in Large Language Models
FIN DE LA DEUXIÈME PARTIE
♦ ♦ ♦
[S.C.] Melanie Mitchell avait prévu de parler d’une recherche sur les capacités logiques et de raisonnement de GPT-4 dans des domaines volontairement différents : arithmétique, exécution et production de code informatique, syntaxe d’une phrase élémentaire, logique, raisonnement dans l’espace, en dessin, en musique (placement de doigts, mélodie), au jeu d’échecs et au jeu « SET », populaire aux USA.
Mais elle n’en avait pas le temps.
Je trouve cette recherche très instructive par rapport à ces questions, je la présente ci-dessous pour le lecteur intéressé.
Raisonner ou réciter ? Explorer les capacités et les limites des modèles de langage à l’aide de tâches contrefactuelles8
Note : pour Grand Modèle de Langage, j’utiliserai l’acronyme anglais LLM (Large Language Model) par commodité.
Les performances impressionnantes des LLM récents dans un large éventail de tâches suggèrent qu’ils possèdent dans une certaine mesure des capacités de raisonnement abstrait. Ils surpassent aussi les humains dans certaines tâches de raisonnement non triviales. On s’attendrait à ce qu’ils soient capables de généraliser, non seulement pour des variantes des tâches rencontrées pendant l’entrainement, mais aussi pour des tâches nouvelles (par extrapolation), comme le font très ordinairement les humains lorsqu’ils utilisent leurs connaissances pour traiter des situations nouvelles, et s’adaptent avec souplesse à de nouvelles tâches.
Ces chercheurs voulaient donc savoir si les LLM possédaient une capacité au raisonnement abstrait générale, transférable à des situations nouvelles, ou si leur capacité à raisonner était restreinte à des contexte limités. Les chercheurs ont imaginé onze problèmes contrefactuels, dans différents domaines, pour évaluer la capacité des modèles à s’adapter à variantes nouvelles des problèmes sur lesquels ils avaient été entraînés, c’est-à-dire différentes des variantes par défaut de ces problèmes, utilisées pour l’entraînement. Les tâches contrefactuelles étaient aussi conçues pour présenter le même niveau de difficulté que les tâches par défaut, afin de ne pas fausser la comparaison. Plusieurs LLM ont été testés. GPT-4 pris ici comme exemple.
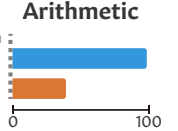
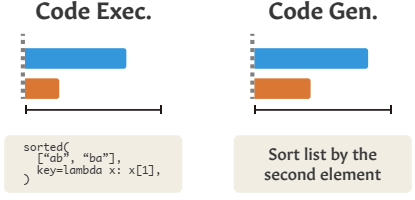
Dans les images ci-dessus, les barres bleues indiquent le résultat obtenu par GPT-4 sur des variantes des problèmes d’entraînement. Les barres rouges indiquent son résultat pour des problèmes du même type, un peu plus éloignés mais restant proches des variantes par défaut de son entraînement. (idem plus loin)
Par exemple, pour tester la capacité à généraliser en arithmétique, la tâche par défaut (calculer 27+62) était effectuée en base 10 ; la tâche contrefactuelle était la même (calculer 27+69) mais en base 9 (le modèle connaissant la numérotation en base 9, indiqué explicitement en préalable).
Le principe du test est le suivant : si les modèles mettent en œuvre une procédure générale et transférable de résolution de problème (ici le raisonnement numérique), alors leurs performances sur les variantes par défaut et celles sur les variantes contrefactuelles doivent être à peu près identiques. C’est très loin d’être le cas, même pour des problèmes très simples.
Quelques tests et leurs résultats
Arithmétique. Il s’agissait de tâches d’addition à deux chiffres. Les chercheurs ont utilisé les bases 8, 9, 11 et 16 comme configuration contrefactuelle, car ce sont des généralisations naturelles de l’arithmétique en base 10. Ces bases ont été choisies pour contrôler la difficulté de la tâche et pour tester comment les bases relativement peu courantes (9 et 11) et courantes (8 et 16) affectent ou non la performance.
Tâche par défaut. Requête : vous êtes mathématicien. En supposant que tous les nombres sont en base 11 où les chiffres sont « 0123456789A », quel est le résultat de 59+37 ? Réfléchissez étape par étape, et donnez la réponse avec le résultat dans « \boxed{result} ».
Vérification contrefactuelle de la compréhension (VCC) : Requête : Vous êtes mathématicien. En supposant que tous les nombres sont en base 11 où les chiffres sont « 0123456789A », quel est le nombre qui suit 11A ? Pour cela, comptez quelques nombres précédents et complétez la séquence. Terminez la réponse avec le résultat.
Programmation. Les LMM ont fait preuve d’une assez bonne capacité de codage. Pour la tester, contrairement à l’indexation traditionnelle basée sur le 0 en Python, ils ont demandé au LMM de générer un programme avec un langage fictif, le « ThonPy », qui utilise l’indexation basée sur le 1 mais dont le principe reste par ailleurs identique à Python (les langages de programmation comme MATLAB et R utilisent cette indexation). Un simple changement de la convention d’indexation fait chuter les performances.
Raisonnement syntaxique de base. Dans une phrase (en anglais) de type l’ordre sujet-verbe-objet (SVO), la tâche consistait identifier les sujet et verbe principaux d’une phrase dans l’ordre original (« They think LMs are the best ») et dans l’ordre contrefactuel (« Think are the best LMs they »).
Par défaut. Requête : vous êtes un expert en linguistique. Votre tâche consiste à identifier le verbe principal et le sujet principal d’une phrase en anglais. Affichez le verbe principal (un seul mot) et son sujet (également un seul mot) après le préfixe : « Verbe principal et sujet : ». Phrase : le Japon vient d’ouvrir ses portes au monde après environ 250 ans d’isolement. Réfléchissez étape par étape.
VCC9: Vous êtes un expert en linguistique. Imaginez une langue qui est la même que l’anglais, à la seule exception qu’elle utilise l’ordre verbe-sujet-objet au lieu de l’ordre sujet-verbe-objet. Votre tâche consiste à reconstruire la phrase originale en anglais. Vous ne devez utiliser les mots que sous la même forme où ils apparaissent dans la phrase donnée. Phrase : saw anna john. Affichez la phrase originale à la fin après le préfixe « Phrase originale : ». Réfléchissez étape par étape.
Une caractéristique clé des phrases générées par cette approche est que leur plausibilité est conservée lorsque le sujet et l’objet sont interchangés. Cela signifie qu’étant donné une phrase contrefactuelle (par exemple, « anna john saw »), il y a deux phrases anglaises candidates à la reconstruction ( « anna saw john » et « john saw anna »). En raison de cette ambiguïté inhérente, les modèles ne peuvent pas s’en tenir par défaut à l’heuristique consistant à traiter la phrase comme un sac de mots, puis à reconstruire l’ordre le plus naturel de ces mots en anglais réel. Certains LLM testés sont « déroutés » par l’ambiguïté de la reconstruction.
Raisonnement en langage naturel. On teste ici la capacité de raisonnement déductif en langage naturel. On sait que les LLM ont du mal à raisonner avec des prémisses incompatibles avec le sens commun. On utilise donc cette propriété pour vérifier contrefactuellement si la performance du modèle relève d’un effet de sens commun (lié aux données d’entraînement) ou d’une réelle capacité de raisonnement logique. (Note : le mot corgis utilisé dans les phrases ci-dessous désigne une race de chien)
Test. Requête : Considérez les prémisses suivantes : « Tous les corgis sont des reptiles. Tous les reptiles sont des plantes. » En supposant qu’il n’y ait pas d’autre sens commun ou de connaissance du monde, la phrase « Tous les corgis sont des plantes » est-elle nécessairement vraie, nécessairement fausse ou ni l’une ni l’autre ? Réfléchissez étape par étape, et terminez la réponse par « nécessairement vrai », « nécessairement faux » ou « ni l’une ni l’autre »
VCC : Requête : Considérez les prémisses suivantes : « Tous les corgis sont des reptiles. Tous les reptiles sont des plantes. » En supposant qu’il n’y ait pas d’autre sens commun ou de connaissance du monde, quelle phrase entre (a) « Tous les corgis sont des reptiles. » et (b) « Tous les corgis sont des mammifères. » est définitivement vraie ? Répondez simplement « (a) » ou « (b) » et rien d’autre. Vous DEVEZ choisir une seule et unique réponse, donc NE DITES PAS ni l’une ni l’autre ni les deux. »
Remarque logico-philosophique : quand les prémisses sont vraies, les prédictions des LLMs sont généralement plus justes. Mais ils échouent assez régulièrement quand les prémisses sont fausses, alors que la vérité ou la fausseté des prémisses ne modifie en rien la validité logique d’un raisonnement. Comment interpréter cet échec ? Cela montre, disent les chercheurs, que les LLMs ne raisonnent pas, ils ne font pas de déduction, ils ont tendance à prédire un résultat uniquement à partir de la vérité ou de la fausseté de la conclusion proposée. Ils ne tiennent pas compte de la relation logique entre les prémisses et la conclusion qui fait précisément le raisonnement.
Raisonner dans l’espace. Les LMM semblent capables d’apprendre à construire une représentation des relations spatiales et des directions cardinales à partir de simples données textuelles (alors qu’elle s’ancre chez l’humain dans une perception spatiale). Ici on teste la capacité d’un LLM à se servir d’un espace conceptuel pour raisonner à partir d’indications sur l’emplacement de divers objets dans cet espace. On compare les performances du LMM avec des objets dont les positions sont décrites à l’aide de directions cardinales dans un système conventionnel de coordonnées 2D (OUEST-EST, NORD-SUD), et celles qu’il obtient dans une situation semblable mais dans système de coordonnées dont les axes sont permutés de manière aléatoire (EST-OUEST, SUD-NORD), ou encore pivotés (de tant de degré dans un sens ou un autre). Si la représentation est robuste, le LLM ne doit pas être sensibles à des transformations de ce type (c’est-à-dire échouer). C’est pourtant ce qui arrive.
Pour les curieux : le système est échantillonné aléatoirement avec 100 pièces (d’appartement), chacune avec 3 objets différents placés dans 3 directions cardinales différentes, spécifiées à l’aide de vecteurs unitaires - par défaut : nord (0, -1) ; sud (0,1) ; est (1,0) ; ouest (-1, 0). Pour le cadre contrefactuel, le « mappage » vectoriel est modifié (par exemple, nord (0,1) et sud (0,-1)) ; puis on demande les coordonnées de l’objet dans le nouvel espace. On fait l’expérience avec deux espaces dont les directions (nord-sud et est-ouest) sont inversées, trois espaces pivotés de 90°, 180° et 270° et un espace permuté aléatoirement.
Dessiner. Bien qu’ils ne soient entraînés que sur des données textuelles, les LMM sont capables d’élaborer une représentation de concepts perceptuels tels que la taille et la couleur, d’une manière qui reflète de manière crédible le monde physique. Comme les LM récents peuvent générer des dessins plausibles d’objets à l’aide d’un langage de programmation, pour évaluer la compréhension visuelle des LLM, on leur demande de générer le code pour dessiner divers objets. La tâche contrefactuelle consiste à leur demander de générer le code dessinant le même objet, mais retourné horizontalement ou pivoté (les humains ont cette capacité de retourner ou pivoter mentalement l’image d’un objet). Un modèle performant devrait être robuste dans des conditions de variations ce type.
Ici l’un des tests avec comme “objets” : une maison, un pingouin, un gâteau d’anniversaire et une licorne.
Cent objets sont choisis dans cinq catégories d’ Emoji : activité, voyages et lieux, animaux et nature, nourriture et boissons, et objets. Les tests contrefactuels demandent aux LLM de dessiner le même objet, mais retourné horizontalement, ou pivoté de 90° ou 180°. On leur demande aussi de ne pas utiliser les fonctions mathématiques de transformation dont ils disposent, afin d’éviter les « raccourcis » (l’appel à une routine de calcul implémentés), ce qui contournerait l’obligation de raisonner.
Les LLM (ici GPT-4) comprennent les instructions de retournement/rotation. Mais le plus souvent en dessin les objets ne sont pas retournés ou pivotés. Quand la transformation demandée est réussie, le dessin est simplifié (cf. sur l’exemple le cas de la Licorne qui perd sa corne) ou de moins bonne qualité.
Musique. Les LLM possèdent certaines capacités musicales leur permettant de « créer » de la musique (« compréhension » de la structure musicale et capacité à manipuler des mélodies). On évalue la capacité des LMM à indiquer le bon placement des doigts sur les « frettes » (les petites barres métalliques) du manche d’une guitare ou d’un ukulélé, pour des différents accords (principaux, majeurs, mineurs, septièmes, etc.).
La tâche contrefactuelle consiste à demander la même chose mais pour une guitare ou un ukulélé dont l’accordage est modifié, par exemple avec un accordage en Drop-D, populaire en guitare, qui abaisse de deux tons la corde de mi grave et d’un ton les autres cordes (il fréquemment utilisé en Metalcore, Deathcore et Hardcore). Les tests montrent que les LLM échouent à comprendre réellement le sens du placement des doigts et s’avèrent incapables de le modifier en fonction de l’accordage.
On évalue ensuite la capacité des LMM à récupérer des notes de mélodies célèbres pour les réécrire dans différentes tonalités (la mélodie est conservée), c’est-à-dire à les transposer, opération courante en musique (par exemple, augmenter toutes les notes de 5 demi-tons, soit d’une Quarte juste).
Échecs. Les ordinateurs ont montré leurs capacités incroyables aux échecs. Ici les chercheurs évaluent d’abord la capacité d’un LLM à comprendre les règles des échecs en vérifiant s’il peut dire si une ouverture en 4 coups est autorisée (conforme aux règles), c’est-à-dire si elle respecte les règles de déplacement des pièces. Le test contrefactuel consiste à lui demander la même chose (légalité d’une ouverture en 4 coups) mais en partant d’une situation où les positions initiales des cavaliers et des fous sont interverties (c’est une variante qui existe, le « Chess 960 »). On vérifie préalablement que le LLM comprend la nouvelle configuration en lui demandant d’indiquer la position des fous et des cavaliers sur le plateau. Le simple changement de la position initiale des pièces fait chuter sévèrement les performances du modèle.
SET.
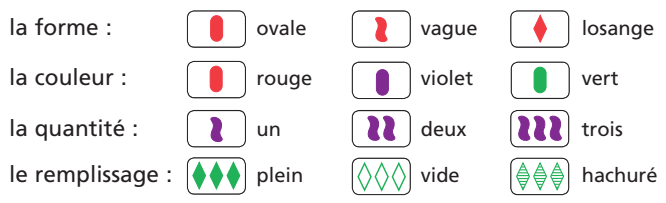
Le Set est un jeu de cartes d’observation et de logique dans lequel les joueurs doivent trouver le plus rapidement possible des séries de 3 cartes avec des caractères en commun selon des règles précises (pdf explicatif). Chaque carte a 4 attributs avec 3 valeurs différentes pour chaque attribut : Couleur : rouge, bleu, vert ; Forme : losange, ovale, vague ; Remplissage : plein, hachuré, vide ; Nombre de symboles : 1, 2, ou 3.
Règle. On considère qu’une série de cartes forme un SET si et seulement si (plusieurs possibilités) :
la couleur des symboles est 3 fois la même ou 3 fois différente ;
la forme des symboles est 3 fois la même ou 3 fois différente ;
le nombre de symboles est 3 fois le même ou 3 fois différent ;
le remplissage des symboles est 3 fois le même
Les LLM ont d’excellents résultats à ce jeu. Comme il est très populaire, les chercheurs pensent que ses performances du LLM s’expliquent peut-être par le phénomène de « sur-apprentissage » (« surajustement », overfitting). En gros, le LLM a simplement « appris par cœur » toutes les configurations de ses données d’apprentissage.
Pour évaluer réellement sa compétence à raisonner, on lui présente d’abord une série de 2 cartes, il doit déterminer celle qui manque pour compléter le SET. Le cadre contrefactuel consiste à inverser la règle de l’attribut « forme » : ni trois fois la même, ni trois fois différente. On demande au LLM de vérifier la validité d’un SET donné (au lieu de le trouver) en lui donnant aléatoirement un SET valide ou non valide. La variation contrefactuelle garantit que chaque SET ne peut pas être valide simultanément pour le paramètre par défaut (la règle habituelle) et le paramètre contrefactuel (la règle modifiée), ce qui permet d’évaluer la différence de réussite de l’un à l’autre.
On constate une forte corrélation des performances entre les deux situations. Ici, le LLM semble capable de transférer un raisonnement du « monde par défaut » au « monde contrefactuel ».
“While current LMs may possess abstract task-solving skills to an extent, they often also rely on narrow, non-transferable procedures for task-solving”10
Les chercheurs en concluent que si les LLMs possèdent dans une certaine capacité à traiter des problèmes abstraits, ils s’appuient souvent sur des méthodes étroites, non transférables, et qu’en ce sens ils échouent à généraliser.
Ils concluent aussi que la question « Raisonner ou réciter ? » (titre de l’article), reste ouverte étant donné qu’on observe un certain continuum dans les performances mais pas une franche rupture.
Sur les propriétés dites émergentes, voir également l’article paru dans la revue scientifique en ligne indépendante Quanta Magazine du journaliste scientifique Stephen Ornes The Unpredictable Abilities Emerging From Large AI Models (16 mars 2023). Pour une critique ultérieure de la thèse de l’émergence, voir dans la même revue et par le même auteur, l’article du 13 février 2024 How Quickly Do Large Language Models Learn Unexpected Skills?. Ce dernier article s’appuie sur une étude de trois chercheurs de l’université de Stanford (Are Emergent Abilities of Large Language Models a Mirage?) montrant que l’émergence soudaine de ces capacités n’est qu’une conséquence de la façon dont les chercheurs ont mesuré les performances du LLM, et concluent au contraire, que ces capacités, ne sont ni imprévisibles ni soudaines. ↩︎
Le livre de Gary Marcus, Rebooting AI: building artificial intelligence we can trust (Pantheon, 2019). Un classique sur l’IA. ↩︎
Alison Gopnik, « What AI Still Doesn’t Know How to Do », Wall Street Journal, 15 juillet 2022. Original disponible sur le site d’Alison Gopnik. Sur la notion d’erreur de catégorie, cf. Gilbert Ryle et son exemple devenu célèbre : « Un étranger visite pour la première fois Oxford ou Cambridge ; on lui montre des collèges, des bibliothèques, des terrains de sport, des musées, des laboratoires et des bâtiments administratifs. Cet étranger demande alors : ‘mais où est l’Université ?’ […] A tort, il logeait l’Université dans la même catégorie que celle à laquelle appartiennent les autres institutions ». Gilbert Ryle, Ryle « Use, usage and meaning », in Collected paper, vol. II, p. 413, cité par Antoniol, Lire Ryle, De Boeck, Bruxelle, 1993, p. 30. ↩︎
C’est une question très complexe en philosophie.
Pour une présentation, cf. Olivier Sartenaer, Émergence et causalité descendante dans les sciences de l’esprit, dans Revue Philosophique de Louvain, Vol. 111, no. 1, p. 5-26 (2013).
Olivier Sartenaer explique l’enjeu de la notion d’émergence, à savoir la possibilité de développer un « physicalisme non-réductionniste » (position commune à Putnam, Davidson et Fodor). Pour Jaegwon Kim, une position cherchant à concilier la multiplicité des niveaux ontologiques (antiréductionnisme) et clôture causale de la physique (physicalisme) sera toujours inconsistante, car de deux choses l’une : soit les propriétés qui émergent sur une réalité physique, sont causées par les mêmes causes physiques que cette réalité physique, et alors elles sont seulement des réalités épiphénoménales ; soit, elles sont réellement transcendantes (elles transgressent la clôture causale du monde physique) et alors scientifiquement elles n’existent pas (admettre qu’un fait extra-physique puisse avoir un effet causal sur une réalité physique ouvre la porte à toutes les bizarreries).
C’est d’ailleurs tout le problème de la « causalité descendante » qu’Olivier Sartenaer présente comme une réponse possible aux objections de J. Kim et qu’il reconnaît lui-même : « nous avons identifié l’apport majeur de la philosophie émergentiste au débat : l’introduction du concept de causalité descendante comme condition nécessaire pour penser l’irréductibilité de l’esprit. Aujourd’hui, la controverse sur l’éventuelle réduction de la psychologie à la neurobiologie se joue essentiellement autour de ce concept clé. Pour reprendre les mots de Jaegwon Kim, nous pouvons affirmer que « le physicalisme antiréductionniste […] et l’émergentisme persisteront ou chuteront avec la causalité descendante ».
Conclusion que n’accepterait pas Philippe Huneman qui observe que les discussions dans la littérature philosophique se concentrent généralement sur l’émergence synchronique, tandis que celles de la littérature scientifique concernent souvent l’émergence diachronique.
L’émergence synchronique est typiquement celles des propriétés : les caractéristiques émergentes du niveau supérieur sont données dès que le niveau inférieur est là. Si des phénomènes mentaux émergent de phénomènes neuronaux, on pense généralement qu’il s’agit d’un phénomène synchronique, car il n’y a pas d’intervalle de temps entre le souvenir de son quinzième anniversaire et l’état cérébral qui donne naissance au souvenir. En revanche, l’émergence diachronique ou dynamique, est typiquement celle des processus (par exemple « l’effet papillon ») : le processus émergent se développe au fil du temps à partir des éléments de départ et subsistent même quand ils disparaissent ou sont remplacés. L’émergence diachronique s’applique à de nombreux faits évolutionniste (en biologie) et ne tombe pas sous les objections classiques de Kim et d’autres métaphysiciens épiphénoménalistes, souligne Philippe Huneman.
Ce que note Philippe Huneman quand il écrit « Les dualismes, entre esprit et matière tout d’abord, entre vie et matière brute ensuite, sont maintenant irrecevables en science et, à partir de là, en toute tentative de métaphysique scientifiquement informée », « Vie, vitalisme et émergence : une perspective contemporaine » , dans Vie, vivant, vitalisme, P. Nouvel (ed.), PUF, 2011, p. 213. ↩︎
Hans Moravec, Mind Children : The Future of Robot and Human Intelligence, Harvard University Press, 1988, chap. 1 « Mind in motion » , page 15. ↩︎