
Distinctive Voices – Melanie Mitchell : The Future of Artificial Intelligence
Suite de la série consacrée à la conférence de Mélanie Mitchell sur l’avenir de l’intelligence artificielle.
Plan de la conférence :
I. Le passé chaotique de l’intelligence artificielle (en deux articles).
Le passé chaotique (1)
Le passé chaotique (2)
II. Un présent déroutant, à la fois étonnant, porteur d’espoirs et de craintes (en deux articles).
Un présent déroutant (1)
Un présent déroutant (2)
III. Un avenir radicalement incertain
♦ ♦ ♦
Un présent déroutant, à la fois étonnant, plein d’espoirs et terrifiant
Étonnantes IA
Beaucoup parmi nous ont probablement déjà utilisé les nouvelles IA génératives comme ChatGPT, DALL-E, Midjourney, et chacun a pu constater à quel point elles sont étonnantes.

L’IA traductrice…
(Nota bene : Melanie Mitchell présente divers essais avec ChatGPT, pour la commodité de lecture, je les ai repris à l’identique en français - les résultats sont identiques)
Le public a découvert les performances étonnantes des IA Génératives avec ChatGPT. C’est un agent conversationnel ou chatbot, en anglais, néologisme formé de « chat » (conversation) et de « bot » (abréviation de robot).

Quand on demande à ChatGPT de traduire la même phrase que celle sur laquelle avait échoué Google Traduction1, sa performance est meilleure, il ne bute pas sur le double sens de « bill ». On peut même lui demander comment il a su quelle traduction de “bill” choisir puisque le terme a plusieurs significations en anglais.
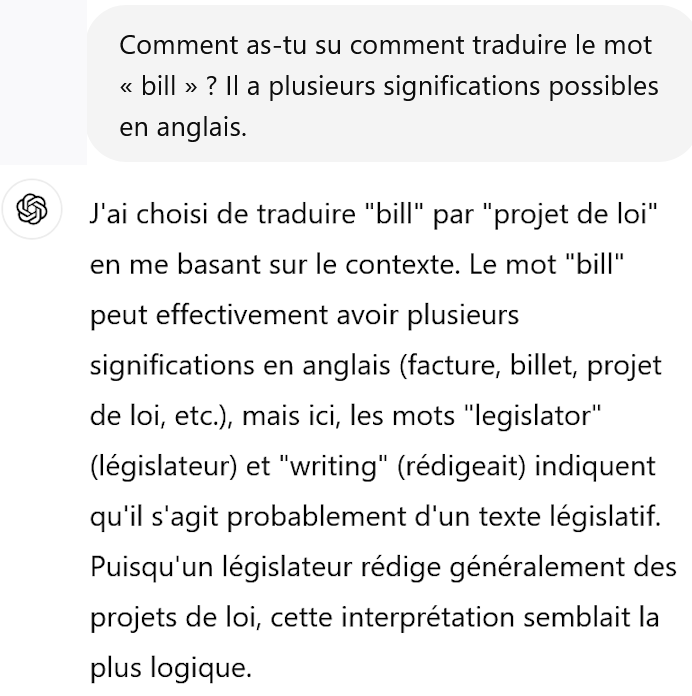
Et il explique - c’est assez verbeux - qu’il a choisi la bonne traduction en fonction du contexte qui mentionne un législateur, etc. ChatGPT semble vraiment accéder à la compréhension du langage. Il opère comme une intelligence humaine disposant d’un bon dictionnaire et choisissant la bonne traduction entre plusieurs possibles en s’aidant du contexte. On a vraiment le sentiment que le système comprend et qu’il nous parle comme un ami.
[S.C.] Ce n’est qu’un sentiment. On le verra plus tard avec l’explication du fonctionnement des agents conversationnels qui simulent des fonctions cognitives et même une certaine tonalité affective. L’impression que la machine comprend, voire nous comprend, repose sur une projection anthropomorphique banale, ici facilitée par l’entraînement de l’agent conversationnel sur des centaines de milliers de conversations humaines et réglé pour les imiter (fluidité, tutoiement, acquiescement « tu as raison », etc.) afin de répondre de manière agréable et positive. Cette projection entraîne des phénomènes d’identification, d’attachement et de dépendance affective au robot conversationnel, notamment dans le cas éthiquement problématique des « robots émotionnels ». Mais c’est un autre sujet. Si le sujet vous intéresse, lisez Des robots et des hommes, mythes, fantasmes et réalité2 de la spécialiste en robotique sociale, Laurence Devillers, plus succinctement l’article « Hikari, la partenaire idéale » (en pdf) de l’artiste plasticien Zaven Paré3 et celui du journaliste Toshiki Miyaza, « Expérience. Ma lune de miel avec Hikari, ma “compagne” artificielle ») dans Courrier International du 21 juin 2020.
L’IA mathématicienne et poète…

Melanie Mitchell souligne dans sa conférence la créativité de ChatGPT. Elle lui a demandé d’écrire une démonstration du théorème de Pythagore en forme d’un poème en faisant rimer chaque phrase.
Elle observe qu’il s’en tire très bien :


Ce n’est pas vraiment une démonstration note Melanie Mitchell, mais on peut lui demander d’écrire la démonstration dans divers styles. On peut ainsi lui demander des choses très étonnantes.
Et en résolution de problème, ce n’est pas mal…

On peut demander à ChatGPT de résoudre des problèmes mathématiques. Par exemple celui-ci : une usine fabrique 5 voitures en 8 heures. Si l’usine travaille nuit et jour, du lundi au dimanche, combien de voitures fabrique-t-elle dans un mois de 30 jours ? Il répond instantanément 450 voitures.
Et si on lui demande « peux-tu expliquer ton raisonnement, s’il te plaît », il répond « bien sûr ! je vais en décomposer les étapes » :

On voit qu’il détaille les différentes étapes du raisonnement, un peu comme un élève qui répondrait à un professeur le questionnant pour vérifier qu’il a bien compris et pas seulement « copié » la réponse. Cette capacité à expliquer les étapes d’un raisonnement a suscité un grand intérêt et un enthousiasme certain, en particulier dans le monde de l’éducation. ChatGPT apparaît comme une ressource pédagogique supplémentaire. Un élève pourrait lui-même demander à ChatGPT de lui expliquer un point de cours qu’il n’a pas compris.
L’IA artiste
Nous avons donc une IA générative qui est à la fois traductrice, mathématicienne et poète. Mais elle peut aussi être artiste. On peut lui demander par exemple de dessiner une coupe de fruits ou lui demander un dessin au trait, par exemple celui d’un bubble tea.


Quoi que vous imaginiez, vous pourrez demander à ChatGPT de le créer. Il l’accompagnera d’une description. L’IA est aujourd’hui capable de faire des choses incroyables. Même les spécialistes de l’IA ont été surpris par ces performances. Cette extraordinaire plasticité ne laisse pas d’être troublante.

[S.C.] Anecdote instructive pour la suite. Vous vous demandez peut-être pourquoi dans ma requête j’ai utilisé l’expression bizarre « saladier de fruits ». Melanie Mitchell avait écrit : « please draw a picture of fruit bowl ». J’ai donc d’abord écrit « S’il te plaît, dessine l’image d’une coupe de fruits ». Mais ChatGPT a étrangement représenté une coupe dont tous les fruits (qui pouvaient l’être) étaient coupés, ce qui est rare dans une coupe de fruits et plus courant dans un saladier. Laissons-lui le bénéfice du doute. Pour l’instant.
Une forme d’intelligence nouvelle serait-elle apparue avec ChatGPT ?

Dans cet article sur les grands modèles de langage, l’un des pionniers des réseaux de neurones, Terry Sevnowsky, chercheur en neurosciences au Salk Institute, affirme qu’un seuil a été atteint. Il décrit ainsi situation :
Quelque chose qui n’était pas prévu il y a encore quelques années commence à se produire. Un seuil a été atteint, comme si un extraterrestre était soudainement apparu, capable de communiquer avec nous d’une manière étrangement humaine. Une seule chose est claire : les LLM ne sont pas humains. Mais ils sont surhumains dans leur capacité à extraire des informations de la base de données mondiale de textes. Certains aspects de leur comportement semblent être intelligents, mais si ce n’est pas de l’intelligence humaine, quelle est la nature de leur intelligence ?4
C’est la vraie question, celle avec laquelle nous sommes tous en prise : quelle la nature de leur intelligence ? À quoi avons-nous affaire avec ces IA génératives capables de prouesses dans des domaines si divers ? à que type d’intelligence ? Quelle est sa robustesse ? Jusqu’à quel point peut-on lui faire confiance ?
On peut déjà s’en faire une idée en dialoguant avec un agent conversationnel comme ChatGPT. Mais auparavant, il faut savoir comment fonctionne un grand modèle de langage.
Comment fonctionne un agent conversationnel ?
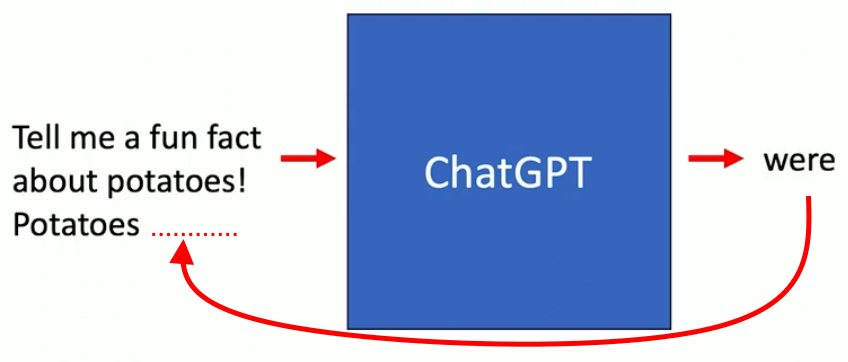
L’idée. Un générateur de texte comme ChatGPT est entrainé à prédire le mot qui suit immédiatement une séries d’autres mots (une phrase par exemple). Il a été entraîné à partir de milliards de segments de textes collectés sur le Web. Il se sert du texte de la question pour prédire le mot qui la suit, le plus probablement. Le mot généré est alors ajouté à la fin du texte initial, l’ensemble forme un nouveau texte qui lui sert à prédire le mot suivant, qui lui-même sera ajouté au précédent, et ainsi de suite. C’est donc un système de complétion automatique. On parle de prédiction « autorégressive », car il utilise les prédictions précédentes comme entrée nouvelle pour déterminer les prédictions suivantes. Tous les grands modèles de langage sont fondés ce type de processus pour générer automatiquement un texte.
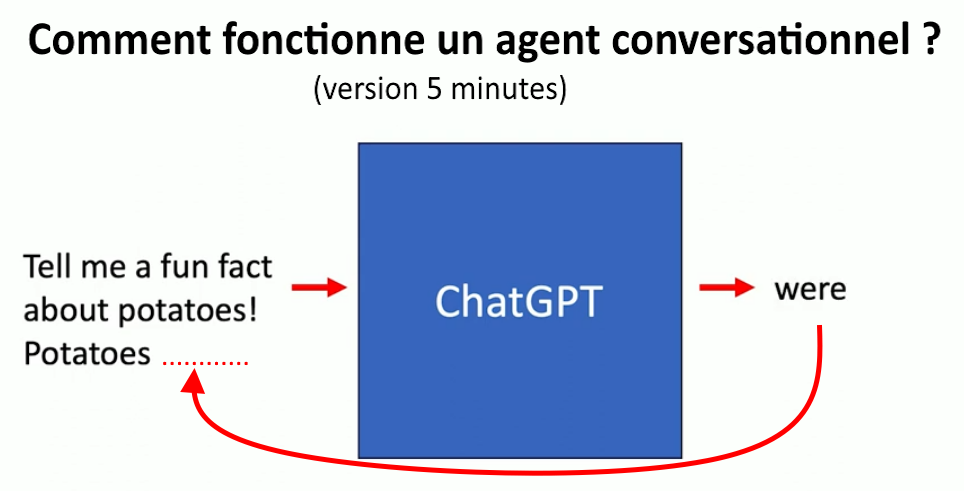
Par exemple, vous demandez à ChatGPT : raconte-moi un fait amusant à propos des pommes de terre. Il commence à générer des mots. La boîte bleue figure le programme qui calcule le mot qui a la probabilité la plus forte de suivre la séquence donnée en entrée.
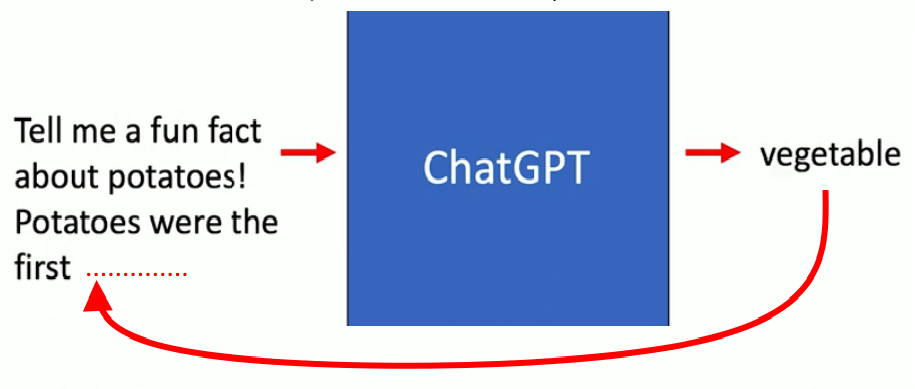
Puis il ajoute ce mot à la requête, et la nouvelle séquence sert à produire le mot suivant. Puis il continue de faire la même chose, génère un texte mot après mot, jusqu’à la réponse finale.
[S.C.] Notion de « token » : le traitement automatique d’un texte commence d’abord par sa décomposition en tokens (« jetons » en français) qui représentent chacun un mot, ou une partie de mot ou encore un caractère comme un point d’exclamation, un morphème dérivationnel (préfixes, suffixes) ou flexionnel (marque du genre, du nombre, etc.). Chaque jeton (token) est porteur d’une information sur le texte. Le système génère la réponse « jeton-par-jeton » (token-by-token), pas forcément mot par mot. Mais dans une présentation que l’on veut simple, on parlera le plus souvent de mots que de « tokens ».
Quand les grands modèles de langage « conversent » avec un utilisateur, ils s’appuient sur une « fenêtre de contexte » qui définit le nombre maximum de mots précédents pris en compte. Cette fenêtre inclut la question posée et la réponse générée. Au-delà, la conversation se poursuit mais le système perd la trace de tout ce qui excède en amont la limite de la « fenêtre » (comme quelqu’un qui oublierait progressivement le début d’une discussion au fur et à mesure qu’elle progresse). On ne s’en rend pas forcément compte, mais cela explique que des incohérences puissent apparaître si l’échange est très long.
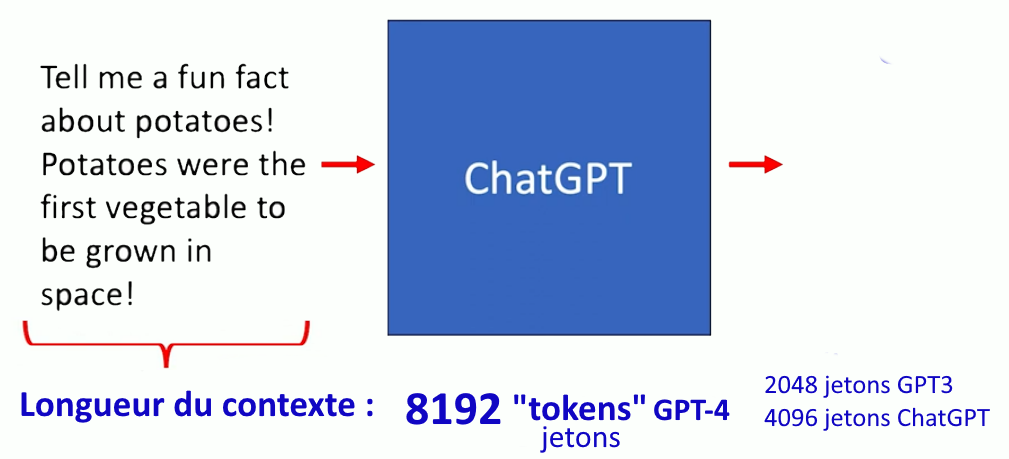
GPT-3, sorti en 2020, avait une longueur de contexte de 2048 jetons (tokens). La fenêtre de ChatGPT (basé sur GPT 3.5) était de 4096 jetons, et la version de base de GPT-4 a une capacité de 8192 jetons (8k), ce qui représentent environ 5000 mots en français (6000 en anglais), soit environ 10 pages (1 mot = 1,5 à 2 jetons en français). La fenêtre de contexte de GPT-4 peut être étendue à 32.768 jetons (32k), soit environ 20.000 mots ou 40 pages de texte. Vous pouvez l’utiliser pour faire un rapport ou écrire une nouvelle, sa « mémoire » de ce qui précède étant plus ample, le résultat en sera meilleur (mais pour cela il faut payer !).
Qu’y a-t-il à l’intérieur de la boîte bleue (CHAGPT) ?
Un grand modèle de langage repose sur un réseau de neurones particulier, appelé « transformeur » (« transformer » ou « transformer network »). Il est un peu plus compliqué que les réseaux de neurones traditionnels (cf. article précédent). Quand on soumet une requête en entrée (c’est le prompt), elle traverse les diverses couches logicielles du réseau de neurones jusqu’à la production du résultat en sortie.
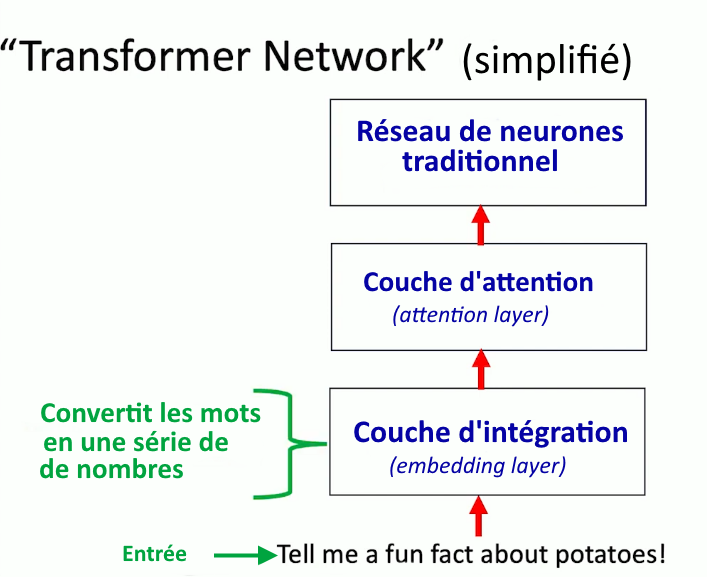
Un « neurone » ne peut pas prendre un mot en entrée. Il ne fait que des calculs sur des nombres (des vecteurs au sens informatique, c’est-à-dire des suites de nombres). Il faut donc préalablement représenter les mots par des vecteurs, c’est la fonction de la couche dite d’intégration5 (embedding layer). Ce processus s’appelle le word embedding (plongement lexical en français) qui transforme les mots en vecteurs. Pour ce faire, la séquence d’entrée est d’abord décomposée en une série de jetons (tokens)6. L’intégration (embedding) transforme ainsi la séquence en une série de vecteurs mathématiques porteurs d’informations syntaxiques et sémantiques.
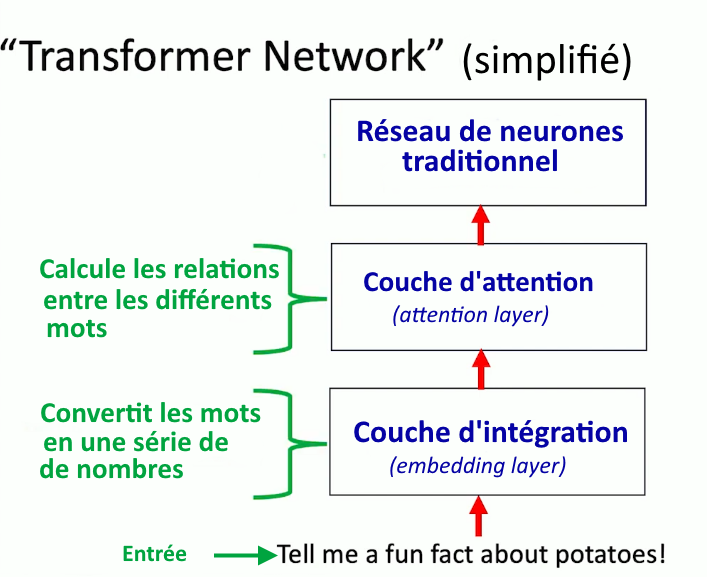
La « couche d’attention » est l’innovation majeure dans cette forme de traitement automatique des langues. Elle a été introduite en 2017, dans un article historique de l’équipe de Google, intitulé « Attention Is All You Need ». Ce mécanisme sophistiqué dit « d’attention » permet de capturer (calculer) les relations entre les mots plus ou moins distants, améliorant ainsi la capacité du modèle à saisir des nuances en fonction du contexte. Ici par exemple, « fun » est un adjectif, il modifie le substantif « fact » ; « Tell me » est une commande qui indique à la machine une tâche : calculer (en quelque sorte) les relations entre ces mots pour prédire le mot suivant le plus plausible (compte-tenu de tous les plongements lexicaux ou relations de « proximité » entre les mots).
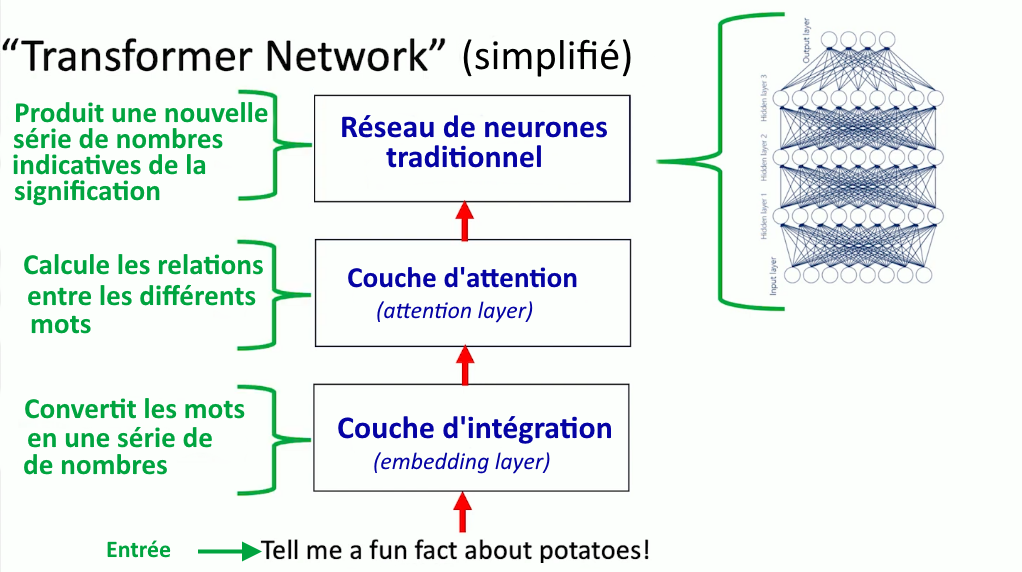
Ces informations sont ensuite traitées par un réseau de neurones profond traditionnel qui génère à son tour une série de nombres représentant des informations sur les différents « mots » (les jetons) de la phrase, et donc sur le sens de la phrase.
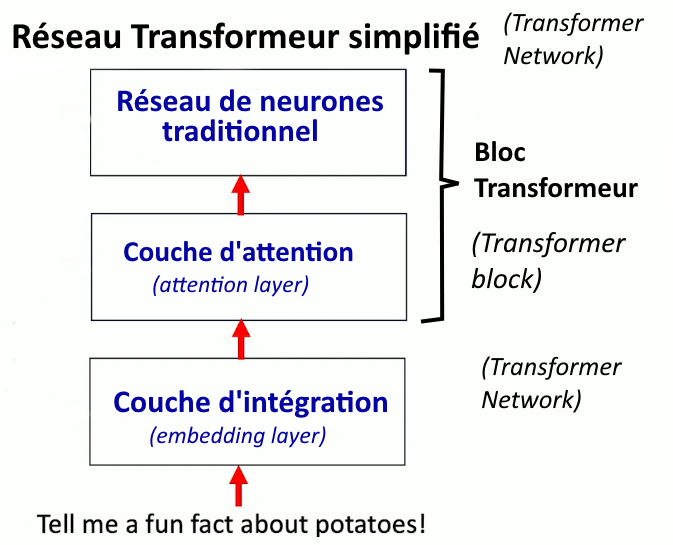
Cette une explication assez vague, mais suffisante pour avoir une bonne idée de ce qu’on appelle un Transformeur (ou Transformer Block), c’est-à-dire l’algorithme (le « réseau de neurones ») qui est au cœur des IA génératives de texte. Il est donc constitué des deux réseaux de neurones (mécanisme d’attention et réseau de neurones traditionnel). Ce type de réseau est appelé « transformeur » parce que le système peut modifier l’état de l’information. Le mécanisme d’attention permet de « peser » (calculer) l’importance des différentes données pour le sens du texte (sur quoi focaliser l’attention ?) et d’attribuer ainsi une valeur aux différentes relations entre les termes. Si on pivote l’image de 90°, on obtient la figure ci-dessous :
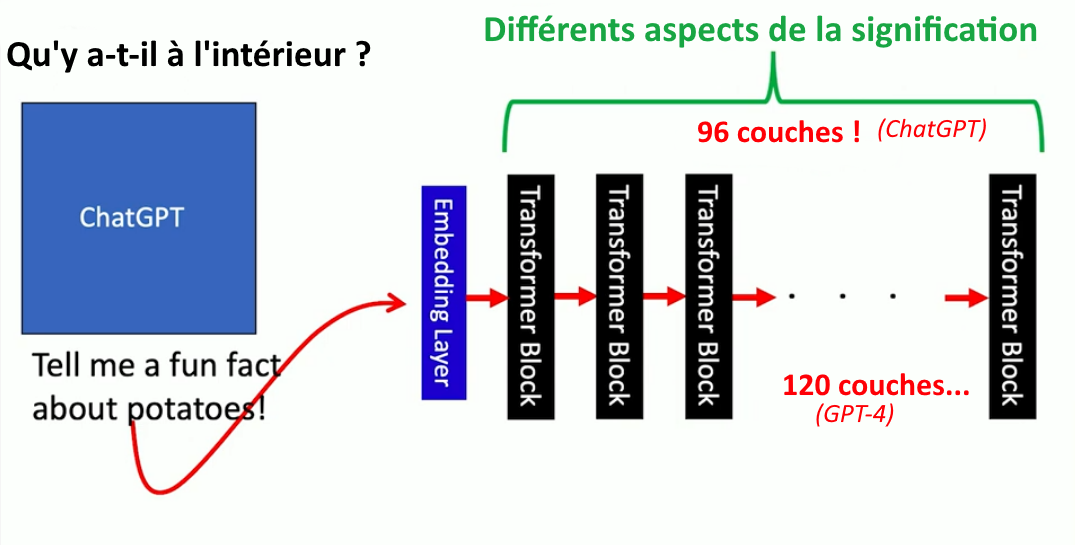
Le transformeur est un réseau très complexe de neurones simulés (avec des connexions pondérées), composé d’un nombre énorme de couches disposées successivement. ChatGPT avait 96 couches de blocs transformeurs, montés en « pipeline » (« à la chaîne »), GPT-4 en a 120. On ne peut évidemment pas exécuter un tel programme sur son propre ordinateur. Il faut de très grands serveurs comme ceux d’Open IA. Le système prend des informations à partir de la requête (le texte en entrée), les encode et alimente ensuite les blocs transformeurs. Chacun de ces blocs capture certains aspects de la signification de la phrase : est-ce un nom ? Est-ce un verbe ? Est-ce que la pomme de terre est un légume ? Que signifie amusant ? fait (fact) ? « fait amusant » (funning fact) ? En fait, nous ne savons pas ce qui se passe exactement à l’intérieur de cette « boîte noire » (ou bleue ici !). Même ceux qui ont créé ce système ne le savent pas, parce que lorsque l’on donne au transformeur des textes pour s’entraîner, c’est lui-même qui met à jour ses paramètres, c’est-à-dire ajuste le poids des connexions entre les neurones. Nous en ignorons le détail (ChatGPT avait déjà 173 milliards de paramètres ! GPT-4, plus de 1700 milliards).
Rappelons-nous ce qui se passe. Pour chaque mot (jeton, tokens) de son « lexique », le système calcule la probabilité qu’il a de venir à la suite du précédent dans le texte à compléter. Le réseau génère en sortie finale une distribution de probabilité sur l’ensemble des mots (jetons) de son vocabulaire.
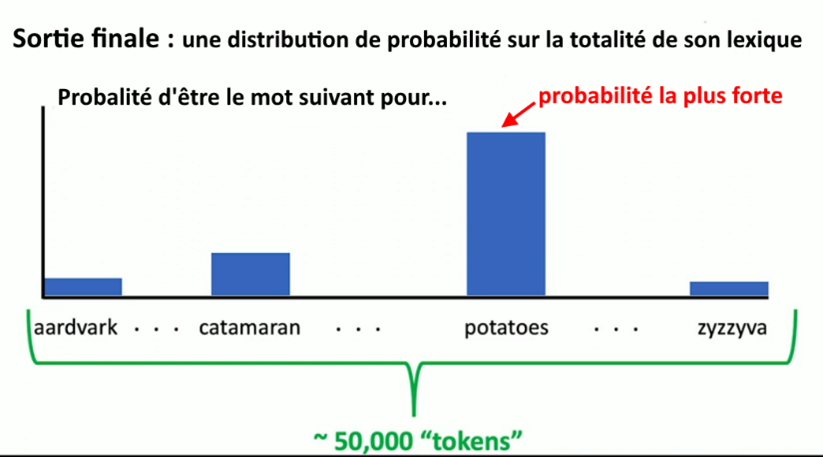
Par exemple, après la requête « Tell me a fun fact about potatoes » (raconte-moi un fait amusant sur les pommes de terre) le système calcule le mot qui a la probabilité la plus élevée d’être à la suite de la séquence, par exemple « potatoes » (les patates), et l’ajoute au morceau de phrase précédent. Il recommence ensuite le calcul pour le mot suivant en fonction du contexte grâce au mécanisme d’attention. Le nombre de jetons (tokens) du système est d’environ 50.000 pour ChatGPT (version 3), et plus de 100.000 pour GPT-4.
[S.C.]. Emily Bender et ses co-auteurs ont qualifié les grands modèles de langage des « perroquets stochastiques »7 : ils ne font que prédire, mot après mot, le mot le plus probable d’après le contexte (le plus plausible pour l’humain, qui lui se sert lui de son “sens commun”). C’est un avis largement partagé dans la communauté IA. C’est aussi ce qui expliquerait certaines limites de ces systèmes : insensibilité à l’incohérence, incapacité à planifier, à organiser, erreurs surprenantes, comme on le verra bientôt.
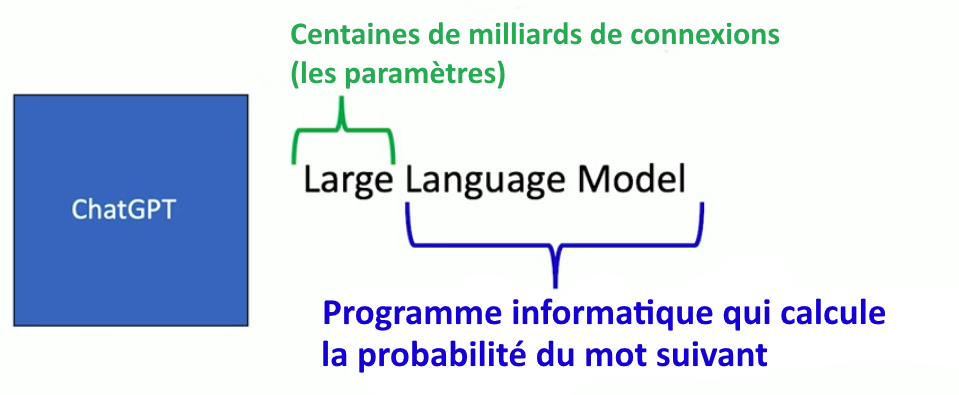
ChatGPT est un grand modèle de langage (Large Language Model). Un modèle de langage parce que c’est un programme qui calcule la probabilité du « mot suivant » dans un texte. Et grand parce qu’il a des milliards de connexions pondérées qu’on appelle ses « paramètres ».
Comment est-il entraîné ?
1° La collecte de données…

Les grands modèles de langage sont entraînés sur des très grands volumes de textes provenant des millions de pages Web, d’écriture de codes informatiques, de conversations sur Reddit, de livres numérisés, etc. Ce dernier cas fait problème parce que l’utilisation des livres numérisés n’a pas été autorisée pour l’entraînement de ces systèmes. Il y a de nombreuses affaires judiciaires en cours pour faire respecter le droit des auteurs.
[S.C.] En français, on dit aussi : modèle massif de langage (Daniel Andler), modèle de langage à grande échelle (documentation technique d’IBM), Benoît Sagot, titulaire en 2023-2024 de la chaire Informatique et sciences numériques du Collège de France, préfère parler de grand modèle de langue et non pas de langage (Apprendre les langues aux machines – leçon inaugurale, explication en 11:14) ou de modèle de langue génératif (Benoît Sagot, Converser avec la machine).

GPT-4 a été entrainé sur 13.000 milliards de « mots » (jetons, tokens) à comparer aux 500 milliards du premier ChatGPT (fondé sur GPT 3.5) lancé en 2022. En lisant à 250 mots par minute 8 heures par jour, il nous faudrait 170.000 ans pour y arriver 8. En comparaison, on estime qu’un enfant de l’âge de 10 ans a lu ou entendu environ 100 millions de mots (le calcul porte uniquement sur les mots « entrants »), ce qui fait 130.000 fois moins que GPT-4 et 5000 fois moins que ChatGPT version 2022. Or les capacités linguistiques d’un enfant de cet âge sont pourtant bien meilleures.
2° L’apprentissage auto-supervisé
Comme tous les réseaux neuronaux de type transformeur, on commence par attribuer une valeur aléatoire aux poids du réseau. On lui donne un morceau de phrase (extrait des données d’entraînement) - par exemple « être ou ne pas » - puis le réseau prédit le mot suivant.
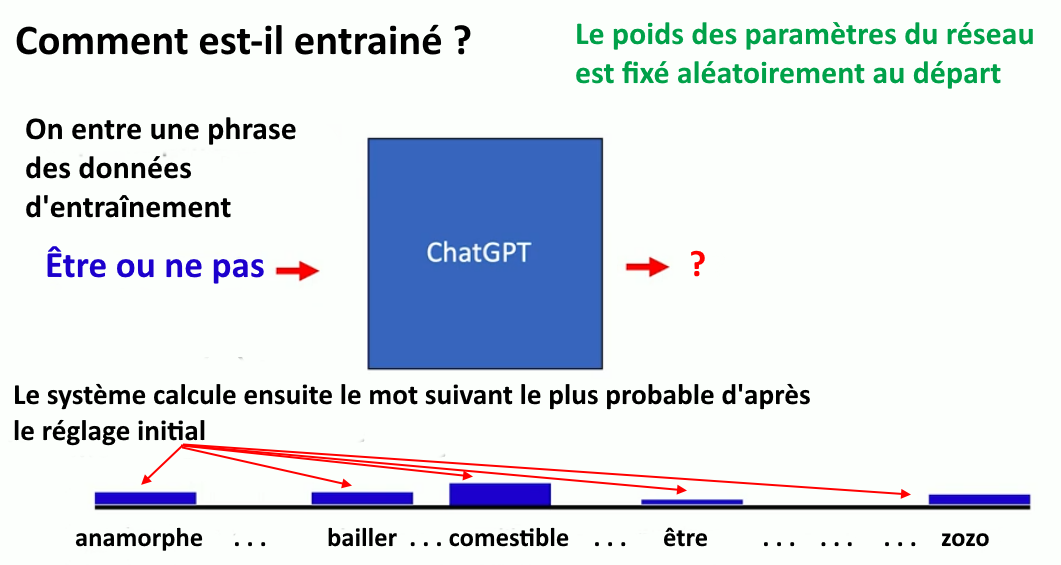
Mais comme au début « le poids » de chaque connexion a été fixé aléatoirement, le système peut, par exemple, prédire « comestible » (la sortie serait alors : « être ou ne pas comestible »). Comme la bonne réponse (« être ou ne pas être ») fait partie des données d’entrainement, le programme de formation lui indique que le mot sélectionné est incorrect, c’est-à-dire qu’il doit modifier les poids de certaines connexions jusqu’à ce que le mot correct ait la probabilité la plus forte d’être sélectionné et le soit. Et l’on répète cela, encore et encore, avec des milllions de phrases.
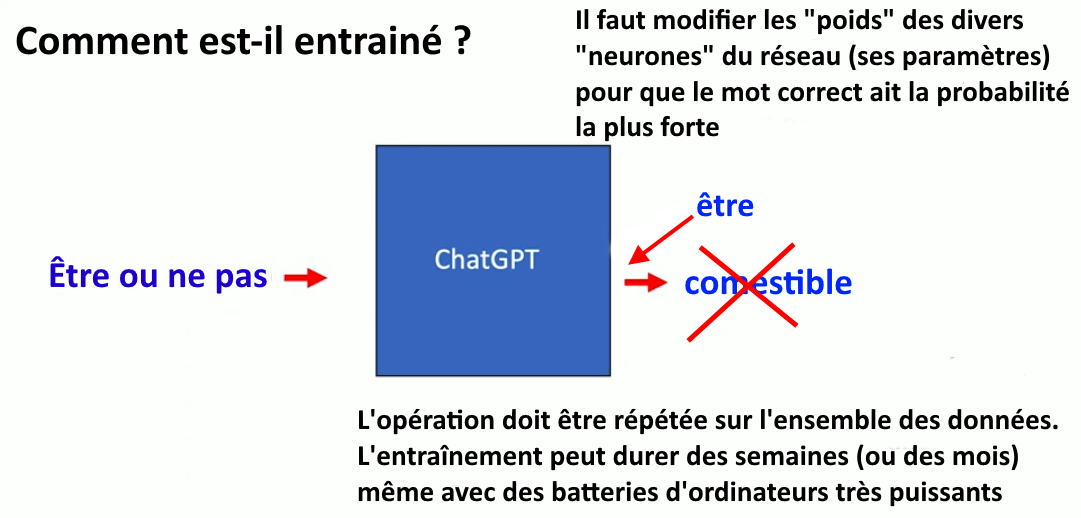
Même pour ces grandes entreprises qui disposent d’énormes centres de données (les data center), avec des batteries (clusters) d’ordinateurs, l’entraînement complet de ces modèles peut prendre des semaines (parfois des mois). Et il coûte des sommes faramineuses : 78 millions de dollars pour GPT-4 d’Open AI, 191 millions de dollars pour Gemini de Google. Cet entraînement a aussi un impact environnemental considérable car il consomme d’énormes quantités d’énergie et d’eau (pour refroidir les serveurs).
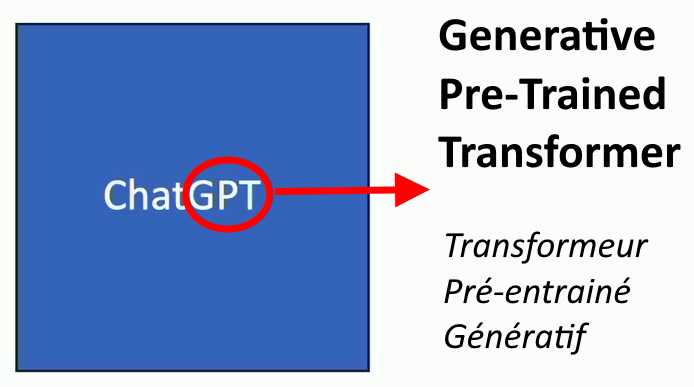
Voilà ce qu’on on appelle un « GPT », un Generative Pre-entrained Transformer (transformateur génératif pré-entraîné) dont les termes ont été expliqués :
- Transformeur, le nom de ce réseau ou programme particulier.
- Pré-entrainé, c’est-à-dire dire formé préalablement sur des quantités gigantesques de textes.
- Génératif, parce qu’il permet de générer des textes nouveaux (aspect créatif) à partir de requête.
[S.C.] Les grands modèles de langage comme les modèles GPT d’OpenAI, Gemini de Google ou Llama de Meta, sont pré-entraînés par apprentissage auto-supervisé à partir d’un corpus massif de données non étiquetées. Lors du pré-entraînement, les modèles reçoivent le début d’un texte tiré des données d’entraînement (« Descartes est un … »), et doivent prédire à plusieurs reprises le mot suivant dans la séquence jusqu’à la fin de la séquence (« Descartes est un / philosophe / français / du / 17e siècle. », par exemple). Pour chaque prédiction, la phrase originale permet de vérifier l’exactitude de la prédiction. Ces modèles sont donc prédictifs (ils doivent prédire le mot suivant) et auto-régressifs : la vérification de la justesse de la prédiction se fait automatiquement à partir des mots précédents au moyen d’un algorithme dit « d’auto-régression ». À la différence des méthodes d’apprentissage supervisé qui nécessitent de grandes quantités de données étiquetées (catégorisées par des êtres humains) pour l’entraînement des modèles - ce qui est coûteux et chronophage, l’apprentissage est dit ici auto-supervisé car le modèle utilise directement la phrase originale présente dans ses données d’entraînement pour se former, c’est-à-dire qu’il s’auto-corrige. Si sa prédiction est correcte, il ne fait rien et passe à un autre exemple. Si elle est incorrecte, il modifie automatiquement ses paramètres et réitère l’opération jusqu’à l’obtention de la bonne réponse.
Comment un GPT apprend-il à discuter ?
En réalité, ChatGPT ne discute pas vraiment, il ne fait que compléter le mot statistiquement le plus probable qui suit une séquence de mots. Pour en faire un agent conversationnel (chatbot) capable de simuler de façon plus réaliste une discussion, il lui faut plus que son apprentissage de la langue sur les milliards de données collectées. Il doit encore apprendre comment des humains discutent, par exemple quand l’un pose une question ou affirme quelque chose, et que les autres lui répondent ou commentent ses propos dans une discussion en ligne (un « chat »).
Les sociétés comme Open AI ont créé un ensemble géant de requêtes (prompts) d’entraînement qu’elles ont collectées à partir des discussions de leurs propres utilisateurs qui dialoguent en ligne sur leurs pages Web.

Supposons que la requête soit « quelle est la capitale de l’Espagne ? ». Le modèle est exécuté plusieurs fois pour obtenir des réponses différentes. Le modèle les engendre aléatoirement à partir de sa base de données, qui est immense et contient toutes sortes de réponses possibles à la requête. Ces réponses peuvent être comme sur un forum de discussion : « qui pose cette question ? », « un pays » « l’Espagne », « Madrid ».

On demande ensuite à des humains d’évaluer chaque réponse fournie par le modèle et d’attribuer un score supérieur à celle(s) qu’ils jugent meilleure(s). Le modèle est entraîné jusqu’à ce que ses réponses reflètent les « préférences » humaines. Le modèle modifie le réglage de ses paramètres de façon à accorder un poids supérieur aux réponses que préfèrent les évaluateurs, c’est-à-dire une plus forte probabilité statistique qui exprime la confiance dans la réponse (par exemple 85% ou 10%).

C’est là qu’intervient une armée d’êtres humains spécialement embauchés pour évaluer les réponses générées Il y a des entreprises qui proposent ce genre de service. Par exemple Amazon Mechanical Turk indique offrir « l’accès à une main-d’œuvre mondiale, à la demande, 24H sur 24, 7 jours sur 7 ». Ce sont des emplois faiblement payés, proposés dans plusieurs pays (souvent en Inde et en Afrique). Cette pratique est fréquente car il y a beaucoup de tâches où les humains restent indispensables, et spécialement l’étiquetage correct des données d’entraînement, par exemple (« chien », « chat », « bull terrier », « siamois », « ornithorynques ») pour les systèmes de reconnaissance d’images. La vérification humaine, le feedback humain, est également requise pour entraîner un GPT à être un « bon » agent conversationnel, le régler finement.
[S.C] L’expression « Turc Mécanique » est une référence à une supercherie fameuse du XVIIIe, la présentation d’un faux automate joueur d’échecs. Pour les chercheurs en IA, elle symbolise ce qui était une sorte de rêve, et un projet scientifique, faire une machine capable de jouer aux échecs. Dans ce contexte, elle renvoie par analogie au travail « à la main » invisible et nécessaire au bon fonctionnement d’un système intelligent artificiel. Mais est-il vraiment intelligent de parler de « Turc mécanique » pour désigner, dans le contexte du XXe siècle, ces armées de travailleurs, justement turcs, indiens, africains - du Sud global en général, déjà astreints à un travail mécanique, dévalorisant et mal payé, au profit des grandes firmes du Web ?
Quand le chatbot Sydney déraille…


Microsoft a dû s’excuser quand Sydney, son agent conversationnel intégré à Bing (son moteur de recherche), a commencé à produire des messages « toxiques ». Un chroniqueur du New York Times dit s’être senti « profondément déstabilisé » lorsque que, conversant avec « Sydney », celui-ci a soudain « déclaré, sans crier gare, qu’il [l]’aimait » et « a ensuite essayé de [le] convaincre [qu’il était] malheureux dans [son] mariage, et [qu’il devrait] quitter [sa] femme et à la place être avec lui ». L’incident a effectivement surpris. Il a aussitôt nourri le fantasme d’une IA devenue « autonome », « incontrôlable » et « dangereuse », largement repris dans la presse, car c’est le genre de nouvelles qui fait vendre. C’est surtout un exemple de réponse indésirable qu’un agent conversationnel pourrait donner à partir de sa base de données avant que le modèle ne soit « policé », c’est-à-dire réglé pour éviter ce genre de déconvenues.
Comment dompter le Shoggoth ?
Un mème a été créé pour expliquer ce qui s’est passé (cf. Why an Octopus-like Creature Has Come to Symbolize the State of A.I. paru dans le New-York Times). La blague est devenue virale dans le monde de l’IA.
{kind=link}
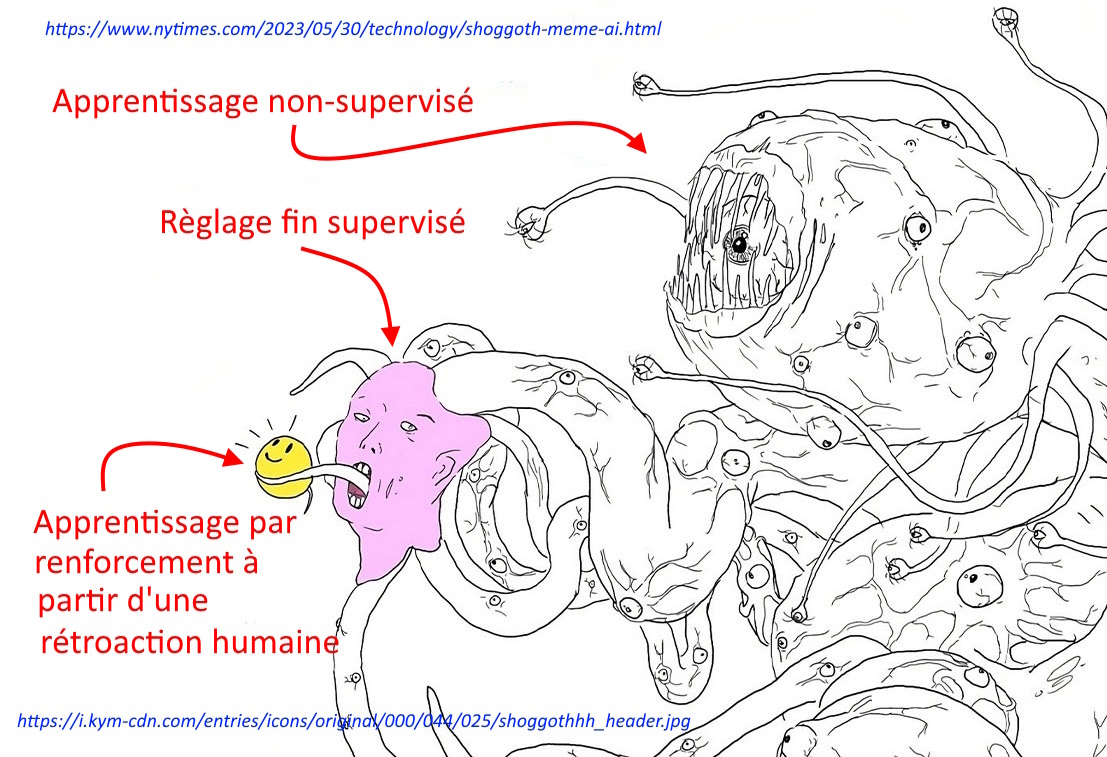
Ce monstre, un Shoggoth, personnage tiré d’une histoire de Lovecraft, représente la partie pré-entraînée du modèle à partir de tout ce qu’on trouve sur Internet et avant tout contrôle par feedback humain. Le système est comparé à ce monstre chaotique parce qu’il a modélisé toutes sortes de données : des savoirs et des choses insensées, des discours brillants et des discours de haine, racistes, sexistes ou dangereux.
Avant la supervision humaine, le modèle est imprévisible : que va-t-il piocher dans sa base de données ? Est-ce qu’il va me répondre comme un professeur de philosophie ou comme un commentateur de CNEWS ? Le monstre a autant de personnalités qu’il y a d’usagers d’Internet.
Pour en faire un gentil agent conversationnel (un gentil chabot), on doit le régler finement (c’est le fine-tuning), procéder à son ajustement, supervisé par un humain. On utilise une technique classique d’apprentissage automatique (de machine learning) : l’apprentissage par renforcement à partir de rétroaction humaine (RLHF pour Reinforcement learning from Human Feedback). C’est ainsi que l’on conduit ChatGPT (ou n’importe quel GPT) à faire ce que l’on souhaite, à devenir un gentil agent conversationnel qui ne dira plus aucune chose vilaine ou offensante. Le petit visage souriant sur le dessin (la sorte de smiley jaune), représente l’interface conviviale derrière laquelle se tient toujours le monstre. C’est une bonne métaphore pour se souvenir qu’il y a cette masse incroyable de données dans ce qu’on appelle le modèle de base (le modèle pré-entraîné), qui a subi plusieurs séances d’apprentissage supplémentaires afin d’en faire un chatbot aimable et poli.
[S.C. : L’apprentissage par renforcement à partir de rétroactions humaines améliore la qualité des réponses parce que le modèle est biaisé afin de produire les réponses s’accordant aux préférences humaines. Il réduit donc la diversité des réponses générées, ce qui est le but visé et un but légitime (comme un modérateur humain le ferait). Il s’ensuit deux inconvénients.
Premièrement : il bride l’imagination. Un modèle réglé pour écarter des réponses fantaisistes, sous-optimales ou controversées, ne fournissant que des réponses conforme au standard HHH (pour Honnest-Helpful-Harmless, « polies, utiles et inoffensives ») écartera peut-être des réponses disruptives, plus créatives qui seraient pourtant meilleures, plus intéressantes, dans une perspective heuristique, c’est-à-dire de recherche et d’invention. La machine est, en effet, déjà conservatrice puisque sa base de données n’est faite que de savoirs par définition passés. Si ChatGPT avait existé à l’époque de Torricelli, un disciple de Galilée, il est très probable qu’il aurait écarté comme inutile (unhelpfull) l’audacieuse hypothèse qui a conduit à la découverte de la pression atmosphérique. Imaginons, écrit Torricelli, un « océan d’air au fond duquel nous vivons submergés… », etc.9 Torricelli raisonne par analogie : la mécanique des fluides est connue ainsi que les problèmes que pose la pression de l’eau (sur un scaphandre à grande profondeur pas exemple). Il propose de raisonner en faisant comme si les gaz étaient des liquides et que l’air avait un « poids ». Si Torricelli avait demandé à ChatGPT « l’air peut-il, comme l’eau, avoir un “poids” ? », notre IA aurait répondu négativement sur la base des connaissances de l’époque. Et ChatGPT aurait probablement ajouté « si c’est vrai, comment se fait-il que nous ne sentions pas ce poids ? » à la manière du mathématicien Roberval (l’inventeur de la fameuse balance) qui déconseille l’expérience sur le vide, avant de s’y rallier. Pour ChatGPT cette « réponse » aurait été inutile (unhelpfull) et controversée (controversial) » - la « querelle du vide » divisant alors la communauté savante.
Deuxièmement : l’ignorance des modalités de la modération (la censure). L’évaluation des « préférences » (le scoring) est obligatoirement faite par des humains. Les créateurs des grands modèles de langage ne livrent pas leur recette : qui a choisi ? comment ? pourquoi ? sur la base de quels critères ? C’est une boîte noire.
Suite de la partie Un présent déroutant… dans le prochain article
♦ ♦ ♦
[S.C.] Comment fonctionne l’apprentissage par renforcement à partir de rétroactions humaines ?
L’apprentissage par renforcement (reinforcement learning) est une méthode d’apprentissage automatique dont le but est d’apprendre la meilleure stratégie de traitement des données pour obtenir le résultat désiré à partir « d’expériences » successives. Il est inspiré du processus d’apprentissage par renforcement mis en évidence par la psychologie comportementale chez les animaux, humains compris. Les algorithmes utilisent un système de « récompenses » et de « punitions » pour « trouver par eux-mêmes » le chemin de traitement optimal vers le résultat final attendu. Les « rétroactions » sont fournies par « l’environnement ». Les termes récompense et punition sont métaphoriques et anthropomorphiques, car il ne s’agit bien entendu que de computations et d’algorithmes.
L’entrainement d’un grand modèle de langage se fait en 4 étapes.
Étape 1 : le pré-entrainement du modèle GPT (Generative Pre-trained Transformer). Il prend un début de phrase dans sa base de données et prédit le mot suivant statistiquement le plus probable. Il complète ainsi le texte mot par mot. Comme il n’est encore entraîné, la prédiction peut être fausse (ou improbable). Il s’auto-corrige en comparant sa prédiction à la phrase originale, et modifie ses paramètres jusqu’à ce que la réponse soit correcte : son apprentissage est ainsi auto-supervisé.
Étape 2 : l’affinement supervisé (supervised fine-tuning) afin que le modèle génère des réponses conformes au format attendu, c’est-à-dire polies, utiles et inoffensives (Honnest-Helpful-Harmless – ou format HHH) grâce à une liste de conversations exemplaires sélectionnées par les experts humains (par feedback humain). Mais l’étape d’affinement supervisé ne suffit pas, parce que la distribution de probabilités des conversations utilisées pour l’ajustement ne coïncide pas forcément avec celle produite après l’entraînement : il suffit d’un petit écart initial dans la formulation de la requête pour qu’après un grand nombre d’itérations (c’est-à-dire de productions successives du mot probable suivant), l’écart s’amplifie au point de produire textes aberrants ou des erreurs qu’aucun humain ne ferait. Comment minimiser la différence (la divergence) entre la distribution issue des données d’entraînement (étape 1) et la distribution issue des données d’apprentissage (étape 2) ? C’est l’objet de l’étape suivante.
Étape 3 : on entraîne un nouveau modèle (un autre programme) appelé « modèle de récompense » (Reward Model) dont la fonction sera d’apprendre au modèle de langage à attribuer un score faible ou élevé aux réponses conformément aux préférences humaines. Le modèle apprend ainsi à prédire le degré de satisfaction des humains en fonction des critères HHH, sans qu’il soit nécessaire de définir explicitement ces critères (comme on le ferait dans une programmation classique de type système-expert). C’est donc par un calcul à l’aveugle sur des valeurs numériques que le système arrive avec une grande efficacité à extraire les caractéristiques (numériques) des bonnes réponses. On s’épargne ainsi les discussions sans fin qu’impliquerait un accord préalable sur une définition explicite des notions de politesse, d’utilité et d’inoffensivité.
Étape (4) : l’ajustement final entraîne le modèle de langage à sélectionner les réponses ayant un score élevé d’après l’évaluation faite par le modèle de récompense. Il s’agit de forcer ce choix en créant un biais dans le processus de recherche de réponse afin que le modèle s’aligne sur les préférences humaines. C’est un entraînement par renforcement car le signal utilisé est un score et non pas des exemples préalablement étiquetés comme corrects par des humains, comme dans le cas d’un entraînement supervisé.
Notes
-
Bill : facture ou texte de loi, selon le contexte, cf. article précédent. ↩︎
-
Laurence Devillers, professeure à l’Université Paris-Sorbonne 4 en informatique et spécialiste des interactions entre homme-machine et de la robotique sociale Des robots et des hommes, mythes, fantasmes et réalité (Plon, 2017). ↩︎
-
Zaven Paré est artiste plasticien. Il a collaboré au Robot Actors Project du professeur Hiroshi Ishiguro, directeur d’Intelligent Robotics Laboratory (Laboratoire de robotique intelligente) et du dramaturge Oriza Hirata, et publié Paré, « Des robots acteurs », dans I. Moindrot & S. Shin (dir.), Transhumanités, L’Harmattan, 2013, pages 223-240. ↩︎
-
Terrence J. Sejnowski, Large Language Models and the Reverse Turing Test. Neural Comput 2023; 35 (3): 309–342 : « Something is beginning to happen that was not expected even a few years ago. A threshold was reached, as if a space alien suddenly appeared that could communicate with us in an eerily human way. Only one thing is clear - LLMs are not human. But they are superhuman in their ability to extract information from the world’s database of text. Some aspects of their behavior appear to be intelligent, but if it’s not human intelligence, what is the nature of their intelligence ? » (page 311). ↩︎
-
Les traductions d’« embedding » sont assez flottantes : on trouve « intégration » , « enchâssement » (Yann Le Cun). La traduction française de Melanie Mitchell utilise « plongement » par analogie avec la notion mathématique de plongement. En traitement automatique des langues (Natural Language Processing), la traduction correcte de word embedding est plongement lexical. L’embedding est aussi utilisé pour représenter des images ou des vidéos (cf. Yann Le Cun, Quand la machine apprend, Chap. 7 : « Dans le ventre de la machine ou le deep learning aujourd’hui », section « Enchâssement de contenu et mesure de similarité »). ↩︎
-
Le processus de traitement d’un texte commence par sa décomposition en unités, les jetons ou tokens (c’est la « tokenisation »). L’objectif principal de la tokenisation est de convertir les données textuelles non structurées en un format structuré qui peut être facilement traité par les algorithmes des modèles. Pendant l’entraînement du système, la tokenisation permet d’analyser et de traiter une langue à un niveau très fin de granularité qui facilite l’extraction d’informations pertinentes pour en élaborer la représentation numérique. Le choix de la technique de tokenisation dépend de la tâche spécifique que doit effectuer le système et des caractéristiques des données textuelles (très variables selon les langues). ↩︎
-
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” dans Conference on Fairness, Accountability, and Transparency (FAccT ’21), March 3–10, 2021, Virtual Event, Canada. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3442188.3445922 ↩︎
-
Source : la conférence L’IA Pilotée par Objectifs de Yann Le Cun du 9 février 2024 au Collège de France. Bien qu’abordant des points souvent techniques, la conférence peut intéresser des non spécialistes car elle aborde aussi de nombreux problèmes (par exemple les limites et failles des LLM) tout en développant des considérations sur l’intelligence comparée à l’IA d’aujourd’hui. Yann Le Cun pense qu’il est possible d’aller vers une intelligence artificielle « de niveau humain » mais explique pourquoi on en est encore très loin. ↩︎
-
Léon Brunschvicg. L’expérience humaine et la causalité physique, Alcan, 1922, page 71. ↩︎