
Cette série d’articles est consacrée à la conférence de Mélanie Mitchell sur l’avenir de l’intelligence artificielle.
Rappel du plan de la conférence :
I. Le passé chaotique de l’intelligence artificielle (en deux articles).
Le passé chaotique (1)
Le passé chaotique (2)
II. Un présent déroutant, à la fois étonnant, porteur d’espoirs et de craintes (en deux articles).
Un présent déroutant (1)
Un présent déroutant (2)
III. Un avenir radicalement incertain
♦ ♦ ♦
I. Le passé chaotique de l’intelligence artificielle. (2)
La révolution de l’apprentissage profond
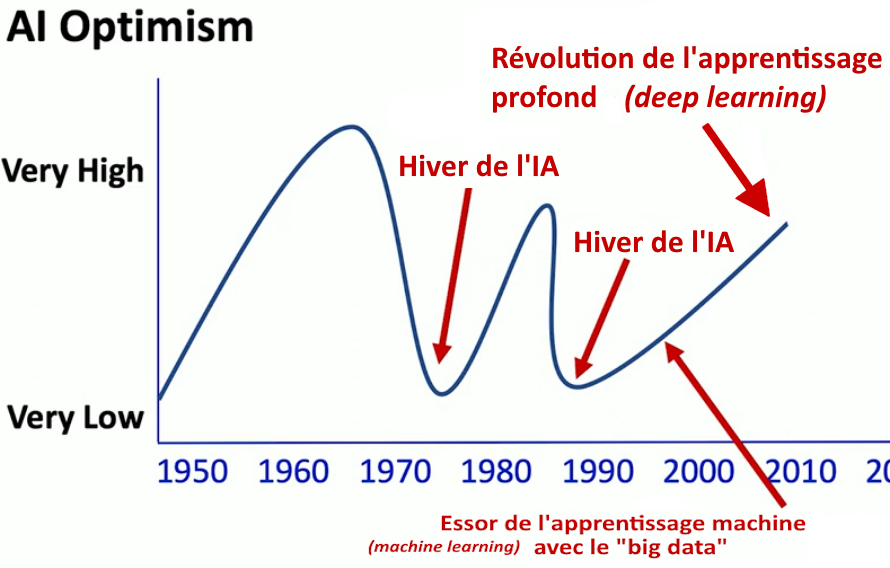
À partir des années 2010 se produit la révolution de l’apprentissage profond » (deep learning), qui prend le dessus sur l’apprentissage automatique (machine learning), et qui inaugure une nouvelle ère de l’IA, celle dans laquelle nous sommes aujourd’hui. L’apprentissage profond repose sur l’utilisation de réseaux de neurones plus grands que ceux utilisés jusque-là en apprentissage automatique.
L’apprentissage profond est devenu populaire après des succès remarquables dans divers domaines, notamment la vision par ordinateur, le traitement du langage naturel, la reconnaissance vocale et même le jeu de Go réputé inaccessible à une « machine » : le programme Alphago de la société Deep Mind (rachetée en 2014 par Google) bat en mars 2016, Lee Sedol, l’un des meilleurs joueurs mondiaux et, l’année suivante, le champion du monde du jeu de Go, Ke Jie, 3 parties à 0.
L’optimisme grimpe en flèche, les annonces spectaculaires se succèdent. Et ce n’est que le début.
Principe d’un réseau de neurones
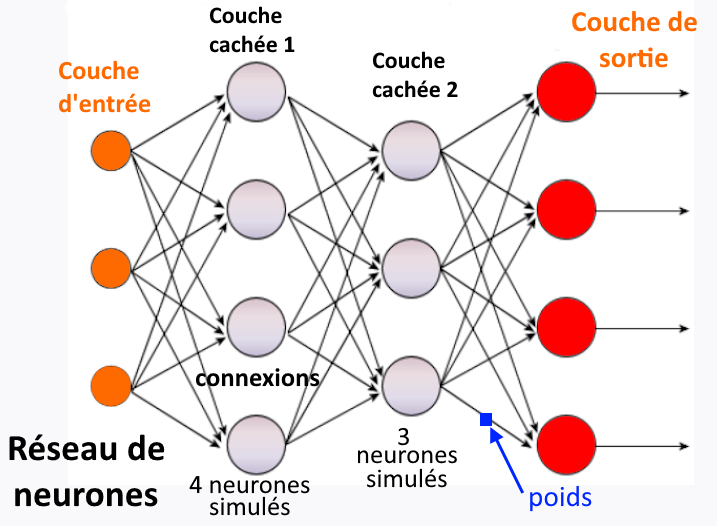
Les algorithmes d’apprentissage automatique (machine learning) utilisent des réseaux de neurones (neural networks). Un réseau de neurones simulés est un modèle informatique composés d’unités de calcul interconnectées (les neurones), c’est-à-dire un ensemble d’équations mathématiques dédié à l’exécution d’une tâche (jouer aux échecs, piloter un robot industriel, trier des images, etc.).
[S.C.] : « neurone », « unité » et « nœud », sont employés indifféremment.
Chaque unité effectue un calcul spécifique. Les unités sont organisées en couches successives. La couche d’entrée (input layer) reçoit les données brutes et la couche de sortie (output layer) donne le résultat du traitement (la réponse du système). Les couches intermédiaires, appelées couches cachées (hidden layer) traitent les données, elles en extraient les caractéristiques pertinentes pour la réalisation de la tâche. Le nombre de couches est variable, de même que le nombre de neurones par couches et le nombre de connexions (un neurone n’a pas forcément besoin d’être relié à tous les autres). Chaque connexion a un coefficient numérique, un poids (weight) qui exprime son importance pour obtenir la sortie finale désirée. Au départ, les poids sont fixés aléatoirement, puis le système les ajuste automatiquement au fur et à mesure de l’entraînement (c’est-à-dire durant sa phase de formation ou d’apprentissage).
[S.C.] Un exemple pour illustrer l’importance de ces couches cachées. Supposons une tâche de classement d’images selon des catégories, par exemple chat et chien. La couche d’entrée du réseau reçoit la valeur de chaque pixel de l’image brute. Cette image est découpée en parties plus petites, traitées par les couches cachées qui leur appliquent des filtres pour détecter des contours, des textures, des formes, etc. À mesure que les informations se propagent à travers les couches cachées, le réseau apprend à reconnaître des caractéristiques plus complexes (des yeux, des oreilles, la truffe, les cuisses, la queue, le pelage, etc.). L’ensemble du traitement permet à la couche de sortie de faire une « prédiction » : indiquer si l’image contient un chat ou un chien.
Les réseaux de neurones profonds (deep neural network)
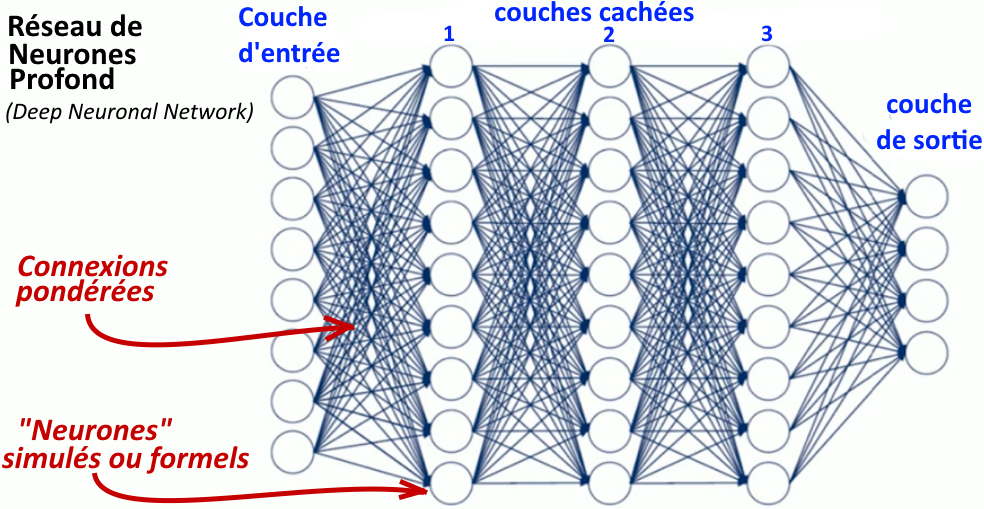
Le « réseau de neurones profond » est l’arrière-arrière-petit-fils du perceptron qui était monocouche, c’est-à-dire composé d’un seul neurone. (sur le perceptron et la première modélisation mathématique d’un neurone, voir l’article précédent).
Un réseau de neurones profond « apprend » comme un réseau de neurones classique : en ajustant automatiquement ses paramètres, c’est-à-dire le poids des connexions (S.C. : voir à la fin de l’article L’entrainement des « modèles » ou réseaux de neurones en IA). C’est la « profondeur » qui différencie un réseau de neurones profond. Il a un nombre plus important de couches cachées (de quelques-unes à plusieurs centaines). Le nombre de connexions et de paramètres (les poids) devient gigantesque : de plusieurs milliers, centaines de milliers, à des millions (voire des milliards dans le cas des réseaux de neurones utilisés par ChatGPT).
[S.C.] C’est l’énormité du réseau qui fait la différence. Le système est capable de capturer (d’extraire) des similitudes et des différences dans des millions de données, d’en construire automatiquement une représentation hiérarchique (les modéliser). Cette puissance le rend particulièrement efficace pour les tâches complexes impliquant de grands ensembles de données, comme la reconnaissance d’images et de parole, le traitement du langage naturel, la voiture autonome.

[S.C] L’effet mystifiant de mot profond. Le grand public n’a entendu parler de l’apprentissage profond qu’avec l’irruption de ChatGPT aux performances impressionnantes. Le terme profond a aussitôt nourri l’imaginaire d’une machine intelligente dotée d’une pensée profonde, de la capacité à aller au fond des chose, de les comprendre en profondeur. Comme les spécialistes de l’IA le rappellent sobrement : le terme « profond » est technique et fait référence au nombre de couches cachées du réseau. Sur ce sujet, on peut lire l’article de Jean-Paul Delahaye, « Intelligences artificielles : un apprentissage pas si profond », paru dans Pour la Science du 30 mai 2018, et plus encore « L’IA zombie : savoir faire sans rien savoir » de Jean-Louis Dessalles, dans son excellent livre Des intelligences TRÈS artificielles (Odile Jacob, 2019) - une excellente introduction à l’intelligence artificielle.
Des performances incroyables
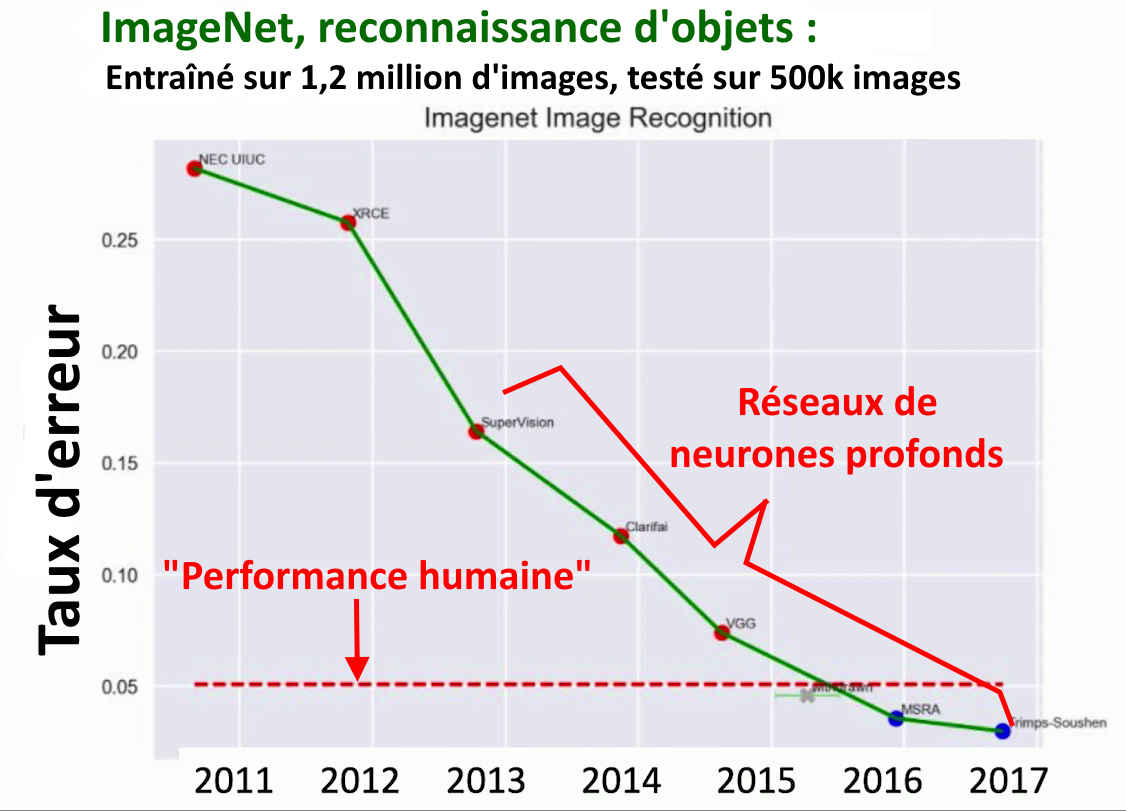
Les réseaux de neurones profonds se sont révélés excellents dans les tâches d’identification sur des images d’êtres vivants, non vivants et d’objets. Ce graphique représente les progrès en reconnaissance d’image, au fil des années, des meilleurs programmes d’IA. Dans le cadre d’un projet visant à stimuler la recherche en vision par ordinateur, un petit groupe a constitué une base énorme d’images, ImageNet, à la libre disposition de tous les chercheurs. Ce groupe organisait chaque année un concours où s’affrontaient les meilleures équipes. L’axe vertical du schéma représente le taux d’erreurs. Plus, il est bas, plus les performances sont hautes, s’il descend c’est donc mieux. On voit qu’avec l’arrivée des réseaux neuronaux profonds, la progression devient spectaculaire. La ligne en pointillés (en bas) représente le taux d’erreur d’un humain. À partir de 2016, les réseaux de neurones profonds surpassent les humains en reconnaissance d’images.
Ces réseaux se sont avérés également performants en « vision par ordinateur ». La reconnaissance d’image identifie des objets (visages ou personnes) sur une image statique. La vision par ordinateur va plus loin. Elle peut cartographier diverses entités dans une scène de rue (personnes, voitures, vélos, feux de signalisation, etc.) et suivre leur mouvement, c’est-à-dire reconnaître en temps réel des objets situés dans des zones particulières du champ de vision d’un système intelligent. Ces progrès ont considérablement accéléré le développement des projets de voitures autonomes.
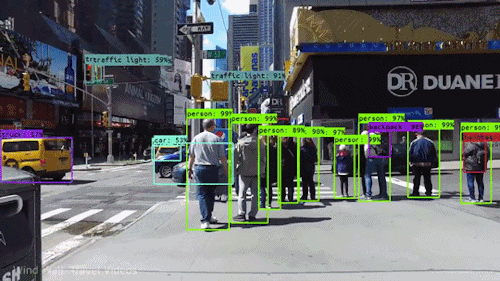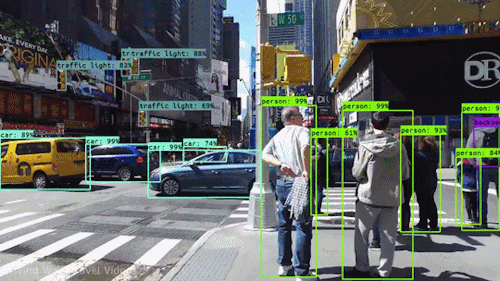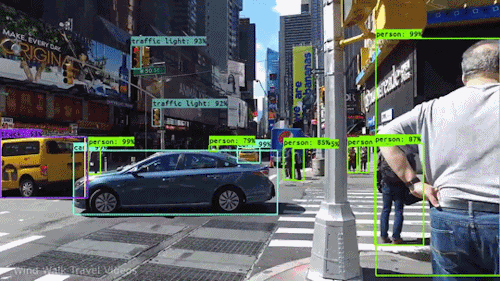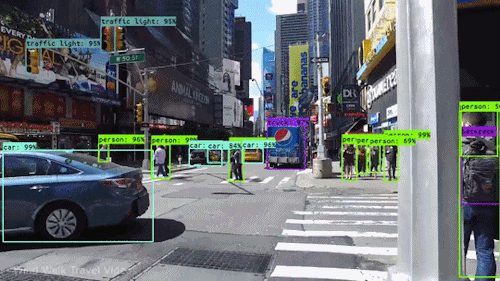

Le battage médiatique autour de l’IA
L’intérêt conjugué de certains chercheurs et des journalistes, les premiers en quête de visibilité, les seconds de sensationnalisme, a nourri la présentation médiatique de ces performances, avec son lot habituel de déclarations définitives et d’exagérations.

Dans le domaine médical, la reconnaissance d’image a permis de réduire le délai de diagnostic avec des résultats exceptionnels : les systèmes d’IA surpassaient les professionnels en exactitude et précision. Les journaux ont aussitôt titré sur le fait que les ordinateurs étaient désormais meilleurs que les êtres humains en reconnaissance et classement d’images.
À cette même époque la reconnaissance vocale fait des progrès importants. En septembre 2016, une étude du département de recherche en IA de Microsoft montre que sa technologie de reconnaissance vocale surpasse les performances des transcripteurs humains1. La presse s’emballe : Technewsworld titre « L’IA de Microsoft bat les humains en reconnaissance vocale ». \
[S.C.] La National Public Radio n’est pas en reste, elle titre son article : « Une étude révèle que les logiciels de reconnaissance vocale battent enfin les humains en matière de dactylographie ».
L’article commence ainsi : « Les ordinateurs nous ont déjà battus aux échecs, à Jeopardy et au Go, l’antique jeu venu d’Asie. Et maintenant, dans la guerre qui fait rage avec les machines, les êtres humains ont perdu une autre bataille, celle de la dactylographie. » Bataille, guerre ? On pourrait tout de même penser à deux choses : 1° au fait que les performances d’un sténodactylo professionnel surpassaient déjà celles de l’humanité ordinaire, sans qu’on y voie pour autant une preuve de leur supériorité menaçante dans une guerre avec le vulgum pecus ; 2° au fait qu’un être humain n’a pas vraiment été conçu pour communiquer avec ses semblables, en tapotant sur le micro-clavier d’un téléphone portable avec ses doigts.

Arriver à battre un humain au jeu de Go était un défi de longue date pour l’intelligence artificielle. En 2016, le programme AlphaGo de Google DeepMind bat le Sud-Coréen Lee Sedol, numéro 3 mondial. La réussite, rendue possible par les réseaux de neurones profonds, fait sensation : « Victoire finale de l’intelligence artificielle » titre Le Monde précisant que « Lee Sedol sauve l’honneur » en remportant une partie sur les cinq [où va se nicher l’honneur !].
Comme par le passé, l’actuel printemps de l’IA met en scène des experts qui prédisent que l’Intelligence Générale Artificielle (en anglais Artificial General Intelligence), celle qui égale ou surpasse les humains, sera bientôt là :
- Dès 2008 Shane Legg, aujourd’hui chef du département d’Intelligence Générale Artificielle de Google DeepMind, prédisait : « Le seuil d’une IA de niveau humain sera franchi au milieu des années 2020 »2 (on en est loin).
- Se fondant sur un sondage, Progrès futurs de l’intelligence artificielle : Enquête sur l’opinion des experts3 réalisé en 2012-2013, les philosophes de l’IA Vincent Müller et Nick Bostrom estiment à 10 % la probabilité d’avoir une d’IA de niveau humain en 2022 et à 50 % pour 2040.
- En 2015, Mark Zuckerberg, PDG de Facebook, déclare : « L’un de nos objectifs pour les cinq à dix prochaines années est fondamentalement de dépasser le niveau humain dans tous les sens humains primaires : la vue, l’ouïe, le langage, la cognition générale. »4
- En 2019, Stuart Russell, co-auteur d’un manuel largement utilisé sur l’IA, estime que « l’IA super-intelligente » « se produira probablement du vivant de [ses] enfants »5.
- Sam Altman, PDG d’OpenAI prédit que d’ici quelques décennies, les programmes informatiques « feront presque tout, y compris faire de nouvelles découvertes scientifiques qui élargiront notre concept de ce “tout” ».6
Limites de l’apprentissage profond
Des erreurs troublantes en reconnaissance d’images

On s’est vite aperçu que les systèmes d’apprentissage profond font des erreurs, qu’il y a des défaillances dans la « compréhension ». Un article de 2017, « Les réseaux neuronaux sont facilement trompés par des objets familiers en position inhabituelle », expose le cas d’un réseau de neurones profond entraîné sur la base de données ImageNet.

Le système reconnaît très bien un autobus sur l’image en (a) avec une « confiance » de 100% (c’est le système lui-même qui calcule la probabilité). Mais il échoue sur d’autres images représentant le bus scolaire dans des positions inhabituelles. Si on fait pivoter l’image avec un logiciel come Photoshop par exemple, le système identifie en (b) un camion-poubelle avec une certitude de 99 %, un punching-ball en (c) avec une probabilité de 100 % et un chasse-neige en (d) avec une probabilité de 92 % dans la dernière.

Même difficulté avec une camion de pompier bien identifié en (a) (99 % de certitude), mais qui devient un bus scolaire (avec une probabilité de 98%) en (b), un bateau pompe (à 98%) en (c) et un bobsleigh (fiabilité : 79%) en (d). Les auteurs soulignent la vulnérabilité de ces systèmes même à des changements minimes apportés à l’image.
La résolution de ce type d’erreur de « perception » n’est pas un problème trivial dans le cas des véhicules autonomes, les environnements routiers étant très variables. Il s’est avéré que ces systèmes étaient beaucoup plus fragiles qu’on ne le pensait. Beaucoup de choses pouvant tromper ces systèmes.
Dans le monde réel, le manque de robustesse de ces modèles est problématique.

On peut penser à certains accidents de la voiture autonome de Tesla, qui a pourtant parcouru des millions de kms sur des routes et autoroutes « normales » sans problème majeur. Quelques accidents étranges ont suffi à remettre en cause la robustesse du modèle comme lorsque le système de vision de cette Tesla s’est révélé incapable d’identifier un camion de pompiers simplement à l’arrêt sur l’autoroute (pour une intervention) provoquant un sérieux accident. Et ce genre d’accident s’est produit plusieurs fois. Sans compter l’excès de confiance qu’engendre l’infaillibilité promise de ces systèmes, comme les nombreux cas de conducteurs dormant au volant de leur Tesla7.
Pour les spécialistes de l’IA, le problème n’est pas l’accident mais sa nature même : comment un système qui pilote un véhicule autonome pendant des millions de kms avec sûreté très supérieure à l’humain peut-il faire des erreurs aussi stupides ? Ce n’est pas rassurant. Cela montre que ces systèmes beaucoup plus performants que les humains en général en reconnaissance d’image, sont facilement mis en échec dans le monde réel ou même par de petites modifications des images.
La conduite autonome au défi de la compréhension du monde.
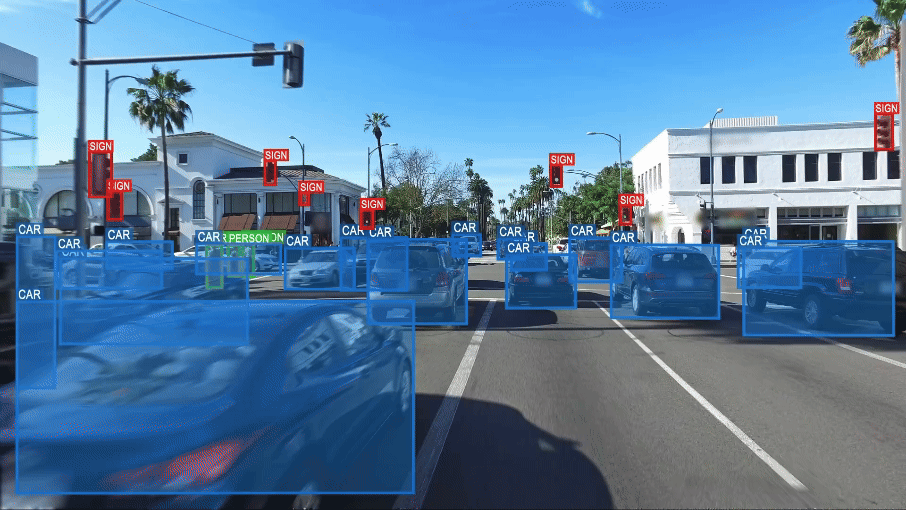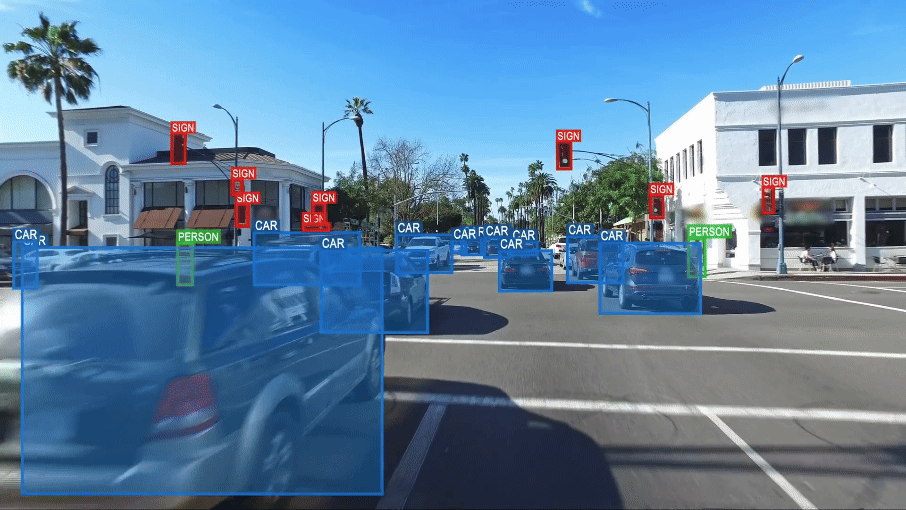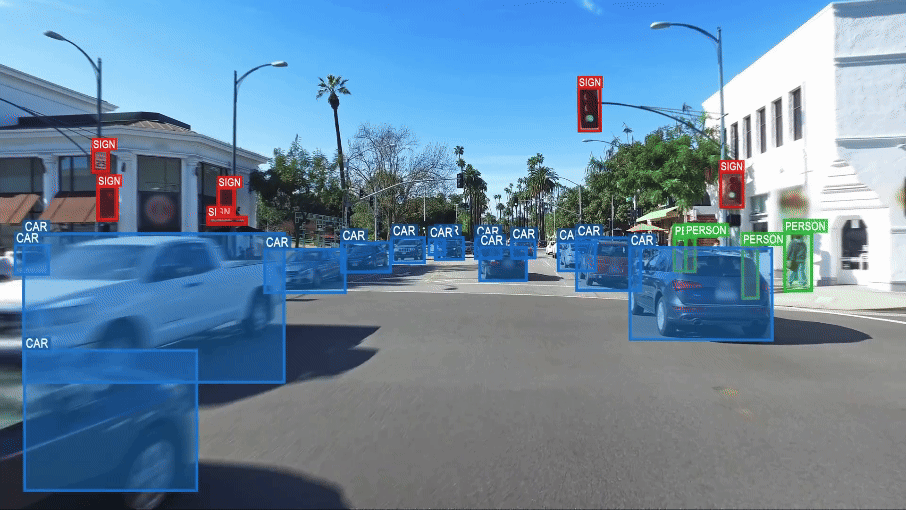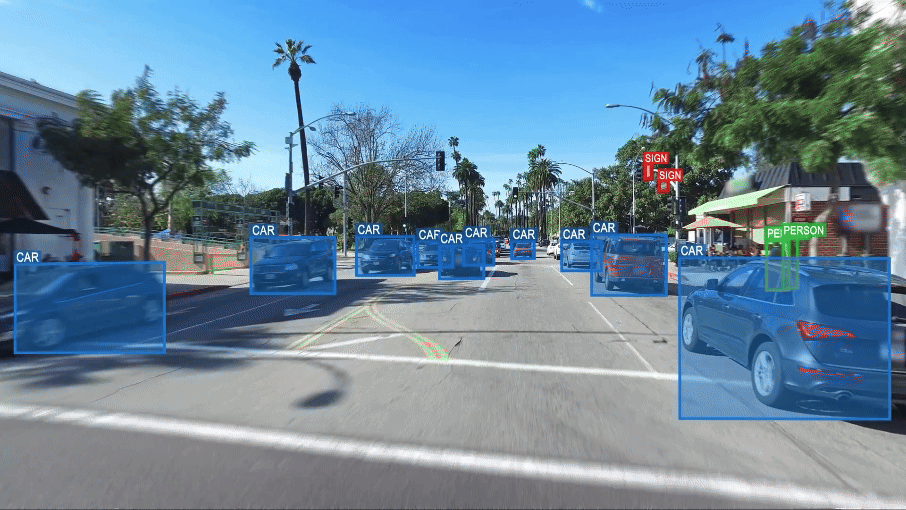
Extrait de How to Build Truly Intelligent AI, Quanta Magazine
Les systèmes de reconnaissance et de vision développés grâce à l’IA semblent dénués de ce que les spécialistes de l’IA appellent le « sens commun » au double sens de cette expression : 1) être capable de porter des jugements sensés, faire preuve de « bon sens » ; 2) et au sens d’Aristote, qui postulait l’existence d’une faculté psychologique assurant l’intégration des données provenant des différents organes sensoriels, rendant ainsi possible leur appréhension générale, c’est-à-dire la faculté de passer des divers éléments perçus par les sens à la compréhension générale de ce qui est perçu.
Pour illustrer ce manque de « sens commun », on peut prendre l’exemple de ce que voit ce système de vision d’une voiture ordinaire.
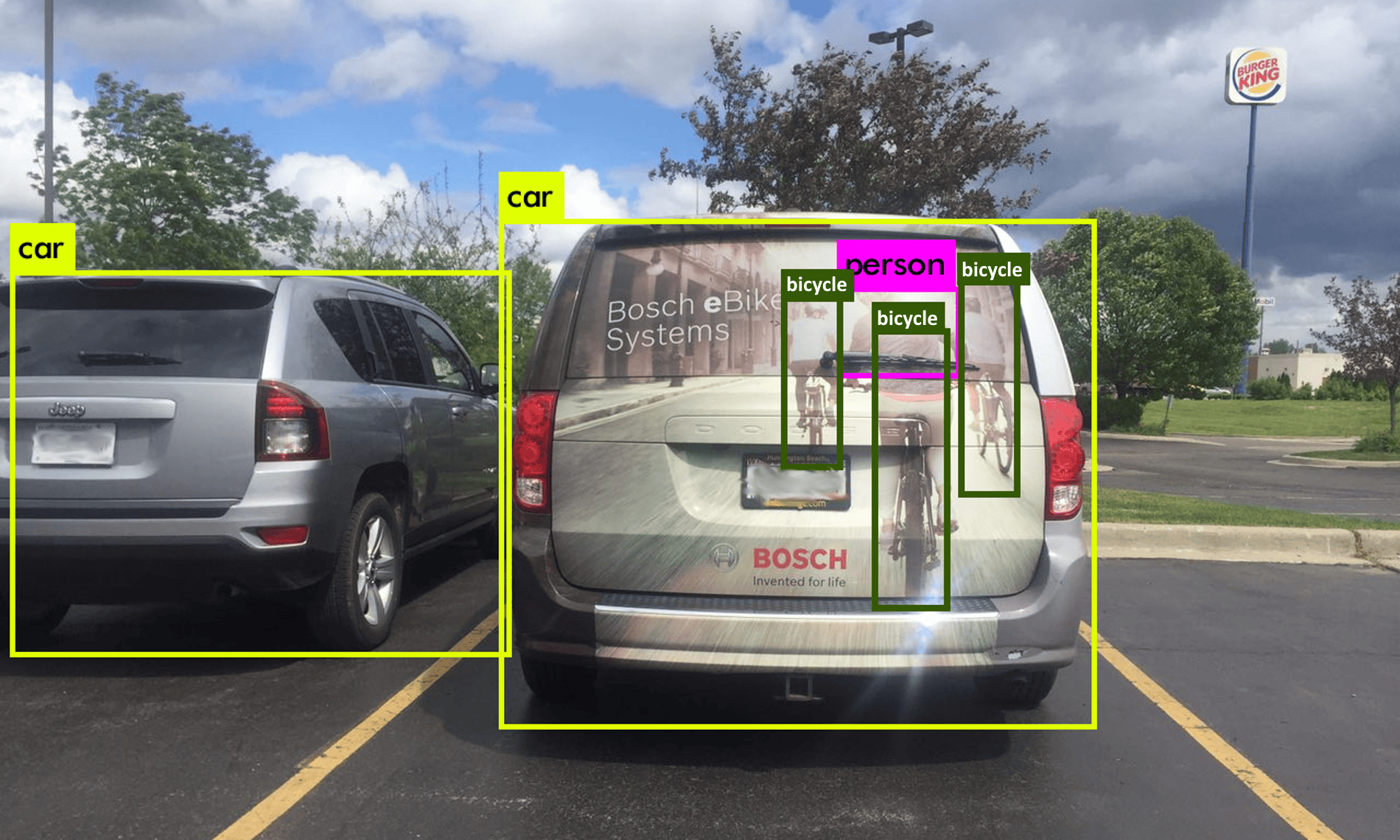
Dans ce cas, il identifie deux voitures, mais aussi trois vélos et une personne sur l’un des vélos. Le système est trompé par la représentation de ces vélos et de cette personne, sur une publicité collée sur le hayon arrière d’un véhicule. Il est incapable de faire la différence entre des entités réelles (objets ou personnes) et ces mêmes entités simplement représentées en image. Pour le système la personne et les trois vélos sont aussi « réels » que les deux véhicules correctement identifiés.
Quand l’IA tombe dans le panneau
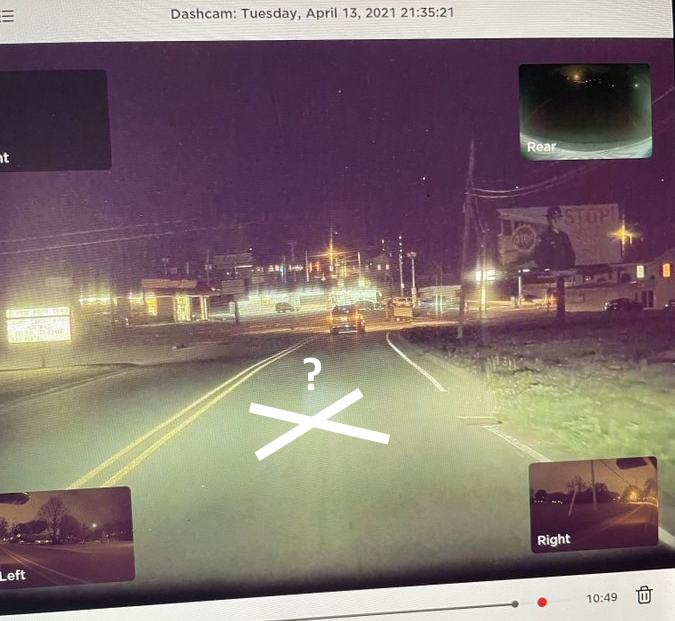
Autre exemple est très connu. Le propriétaire de cette Tesla, Andy Weedman, tweete à Elon Musk que sa Tesla en mode conduite autonome n’arrêtait pas de freiner et de s’arrêter à un endroit de la route où aucun feu rouge n’est visible et où il n’y a ni panneau stop ni aucune sorte de signalisation. Qu’est-ce qui peut donc provoquer son arrêt ?

Après quelques trajets, il remarque un affichage publicitaire sur la droite de la route, représentant un policier brandissant un panneau stop. Ici encore le système n’est pas capable de distinguer représentation et réalité, panneau stop sur une affiche au bord de la route et vrai panneau stop, provoquant l’arrêt inattendu du véhicule (ce qui peut être dangereux si s’autres véhicules suivent). Une erreur que même le plus mauvais des conducteurs ne commettrait pas.
De nombreux cas semblables jettent un sérieux doute sur la possibilité pour les véhicules autonomes d’atteindre la complète autonomie, celle de niveau 58 où le conducteur est superflu, annoncée tous les deux ans par Elon Musk depuis 10 ans. Même le niveau 4 (le conducteur n’est pas indispensable mais surveille) suppose des conditions particulières, définies au préalable par le constructeur, comme la circulation sur des routes spécifiques, cartographiées et éventuellement préparées par le constructeur.
Cela montre que les systèmes intelligents fondés sur des réseaux de neurones profonds ne comprennent pas le monde réel. Ils apprennent sur des quantités de données énormes et sont extraordinairement performants. Mais dans le monde réel se produisent toujours des évènements très ordinaires qu’ils sont incapables d’analyser correctement.
Ce qui pose une question cruciale : qu’apprennent au juste les réseaux de neurones profonds ? Visiblement, même après des centaines d’heures d’apprentissage sur des millions d’images, ces systèmes sont incapables de comprendre les contextes, à la différence de l’enfant qui, à moins d’un an, ne confond pas son doudou, son père ou sa mère, avec leur représentation en photo ou sur un poster.
Qu’apprennent exactement les machines ?
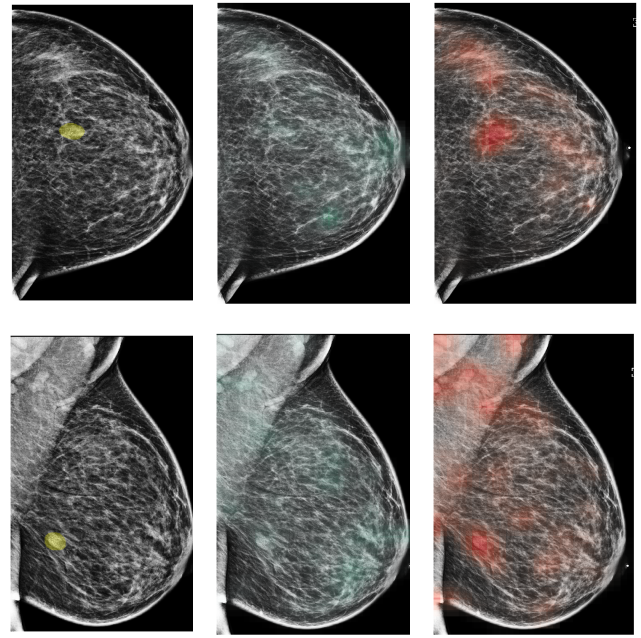
Ces défaillances conduisent donc à se demander ce que ces systèmes apprennent vraiment quand on les entraîne. Pour le comprendre, prenons de l’assistance au diagnostic médical grâce à l’IA. Les systèmes intelligents fondés sur les réseaux de neurones profonds sont très utilisés et avec succès pour l’analyse des données en imagerie médicale (radiographie, IRM, etc.). Par exemple, pour détecter des tumeurs sur une mammographie. (Cf. l’article Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening d’où cette photo est extraite).
[S.C.] Entraînés sur 200 000 examens représentant 1 million d’images, la fiabilité des systèmes d’IA dépasse celle des radiologues humains. Plus précisément, elle égale celle des radiologues très expérimentés mais surpasse celle des autres, notamment les plus jeunes. L’article souligne qu’un radiologue ne se contente jamais d’analyser une image médicale pour poser son diagnostic. La mammographie de dépistage n’est que la première étape d’un diagnostic, la décision finale (pratiquer une biopsie par exemple) n’intervient, en général, qu’après d’autres examens (mammographie supplémentaire, échographie, entretien avec la patiente pour connaître les antécédents, etc.). La recherche montre aussi qu’un modèle hybride, c’est-à-dire combinant un système automatisé et un radiologue, obtient des performances meilleures que l’un ou l’autre pris séparément9.

De même, dans cette étude de 2017, les chercheurs sont fiers d’annoncer que des réseaux neuronaux entraînés, sur des images de lésions cutanées, arrivaient à classer les mélanomes malins et bénins en égalant les performances des dermatologues expérimentés. Il n’en fallait pas plus pour considérer que les réseaux de neurones profonds pourraient bientôt remplacer les dermatologues : un patient n’aurait plus qu’envoyer une photo prise avec son smartphone pour avoir un diagnostic, rendant ce service médical accessible à des millions de personnes, y compris dans avec un système de santé peu développé, et à faible coût.
Mais des anomalies interdisent de considérer ces systèmes comme parfaitement fiables, autonomes à 100 %. Une anomalie avait d’abord retenue l’attention. Ces systèmes intelligents réussissaient très bien l’épreuve de validation de leur modèle ; elle consiste à les tester sur des ensembles d’images pris dans la base d’entraînement mais jamais « vues » auparavant. Bien que triomphant des tests de validation, leurs performances s’écroulaient incompréhensiblement en situation réelle, c’est-à-dire devant des images nouvelles n’appartenant pas à la base d’entraînement.
L’examen de la façon dont les modèles font leurs prédictions est une étape importante pour faire suffisamment confiance aux résultats des modèles pour les utiliser. C’est donc ce à quoi se ont attelés les chercheurs.
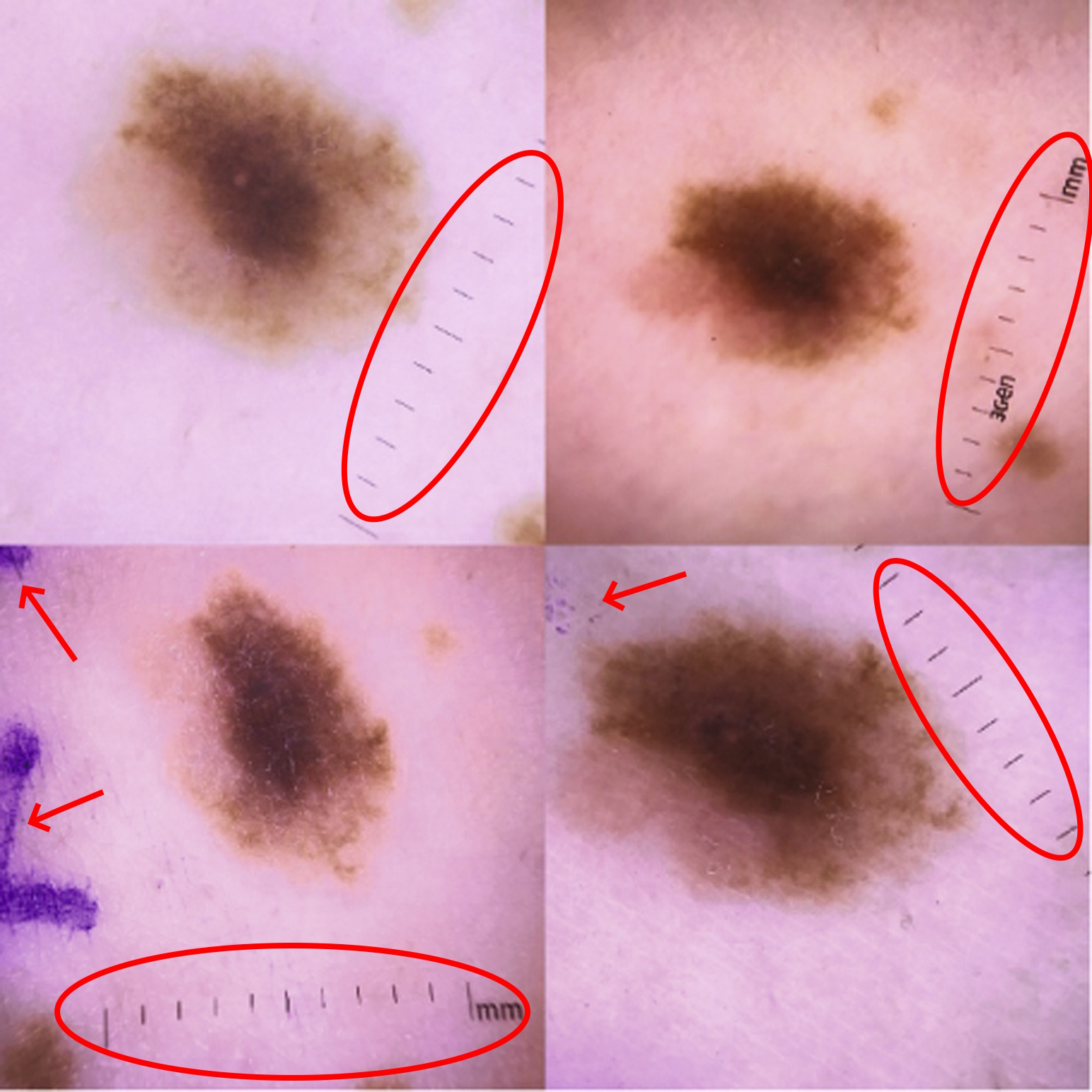
L’une de ces études (Automated Classification of Skin Lesions: From Pixels to Practice) a alors montré que pour identifier les grains de beauté susceptibles de provoquer un cancer, le système recherchait en fait la présence d’une règle graduée sur les clichés. Et cela, parce que les photos utilisées pendant l’entraînement, étaient des clichés médicaux (donc pris et annotés par des professionnels) qui incluaient souvent une règle pour mesurer la taille d’une anomalie suspecte [S.C. : sur l’image, j’ai indiqué un autre artefact mis en évidence par les chercheurs : les traces violettes d’annotation].
L’algorithme a donc appris « par inadvertance » que la présence d’une règle graduée était prédictive d’une tumeur maligne. C’est un « raccourci » très efficace, et qui il fonctionne pour les données nouvelles mais semblables aux clichés médicaux. Comme dans le monde réel, les photos envoyées par les patients ou prises en première intention par un médecin, n’incluent pas de tels artefacts, le système intelligent concluaient logiquement à l’absence de lésions potentiellement cancéreuses10.
Plusieurs études ultérieures ont aussi montré la fragilité de ces systèmes par des contre-épreuves11, des variations de conditions, de nature de cliché, etc.
Qu’est-ce que l’anecdote révèle ?
Premièrement que nous ne savons pas ce que ces systèmes apprennent vraiment. Deuxièmement, qu’ils apprennent souvent autre chose que ce que l’on voudrait qu’ils apprennent. Troisièmement, et de nouveau, que ces systèmes sont dénués de tout sens commun12. Ils excellent dans les diagnostics et mais dans l’analyse des caractéristiques du cliché, ils ne font pas la différence entre de la peau et un instrument de mesure.
[S.C.] Ces recherches ne conclut pas à l’inutilité de l’IA pour le diagnostic médical. Bien au contraire, car ses performances sont indéniables. Elles servent, d’une part, à attirer l’attention des ingénieurs sur la qualité des ensembles de données utilisés, les nombreux biais possibles, pour qu’ils les améliorent. D’autre part, à rappeler que même avec des performances exceptionnelles, voire supérieures à l’humain, il serait imprudent de confier aux systèmes intelligents artificiels, et à eux seuls, sans contrôle humain, un diagnostic médical ou une quelconque décision.
« Lost in translation »
L’utilisation des IA a révolutionné non seulement la reconnaissance vocale (parole vers texte et texte vers parole), mais aussi celui de la traduction multilingue. Mais en dépit de performances considérablement améliorées ces dernières années, ces systèmes restent fragiles.
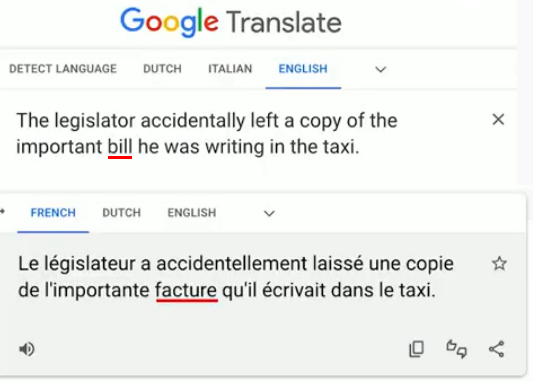
Considérons l’exemple suivant qui vient de Google traduction. On lui demande de traduire la phrase anglaise « The legislator accidentally left a copy of the important bill he was writing in the taxi » (« le législateur a accidentellement laissé une copie d’un projet de loi important qu’il était en train d’écrire dans un taxi »). Google traduction échoue parce que « bill » a plusieurs significations en anglais. Il le traduit faussement par « facture » (statistiquement plus probable) au lieu de « projet de loi », car il est insensible au contexte (pourtant clair ici).
♦ ♦ ♦
[S.C.] Quelques exemples supplémentaires :
Depuis la conférence, la traduction de « bill » dans ce contexte a été rectifiée. Mais les erreurs liées à l’ambiguïté sémantique demeurent, comme on va le voir avec des tests, réalisés au mois août 2024, et inspirés d’une conférence de Jean-Louis Dessalles (Some current limits of Machine Learning and beyond, in the light of AIT).
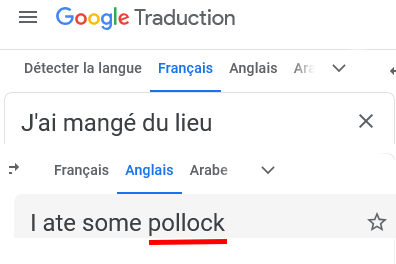
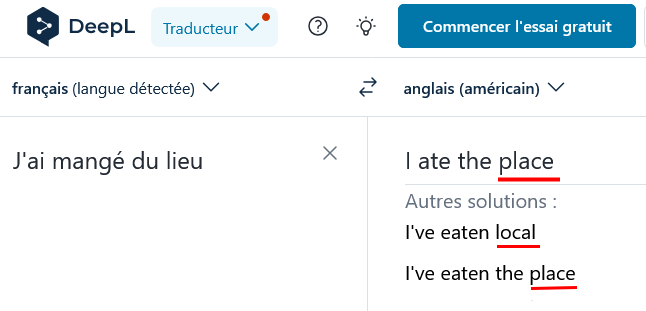
On voit que Google Traduction traduit correctement la phrase « j’ai mangé du lieu » (I ate pollock), ce qu’il ne faisait pas il y a peu.
Mais Deepl échoue : il ne comprend pas que le lieu désigne dans ce contexte un poisson, ni ce qu’il fait, avec cette traduction complètement absurde « j’ai mangé un endroit » (I ate place) alors qu’il réussit le test, si on précise dans la phrase « j’ai mangé du lieu jaune » (correctement traduit alors par « pollock »).
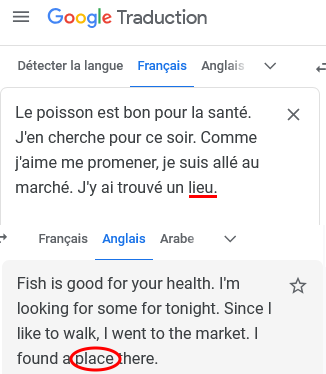
L’IA de Google traduction serait-elle plus intelligente que celle de Deepl ? Peut-on dire qu’elle comprend mieux ? Pas vraiment, comme on le voit sur ce deuxième exemple où Google traduction échoue (tout comme Deepl sur cet exemple).
En revanche, si on précise à la fin de la phrase « … J’y ai trouvé un lieu jaune », Google Traduction traduit correctement lieu jaune par « pollock ». Mais Deepl échoue encore même avec cette précision.
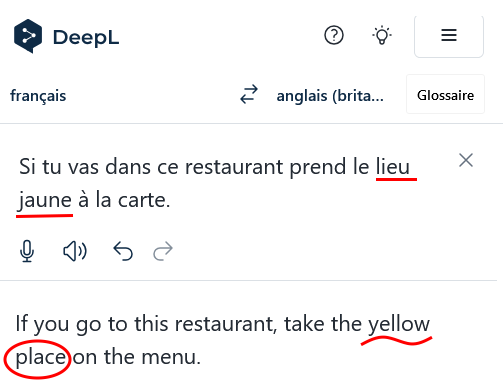
Même si pour Deepl on raccourcit le texte afin de minimiser la distance entre le mot « lieu » et plusieurs éléments de contexte, en espérant ainsi diminuer l’ambiguïté, c’est encore l’échec, alors que Google Traduction traduit correctement : « If you go to this restaurant, order the pollock from the menu ».
Comme Deepl propose souvent des traductions meilleures, il faut en conclure que son modèle n’a pas été entraîné sur des textes français relatifs à la cuisine du poisson… ou pas en nombre suffisant pour “apprendre” et se corriger.
♦ ♦ ♦
Les systèmes de traduction automatique ont aussi des effets dans le monde réel

On les utilise dans de nombreux domaines, parfois très sensibles. Aux États-Unis Google traduction sert à traduire les demandes d’asile des réfugiés. L’article ci-contre signale le danger des erreurs de traduction pour les demandeurs légitimes d’asile. Elles sont nombreuses, et plus nombreuses encore quand il s’agit de langues moins « courantes » (traduire du patcho ou du wolof vers anglais par exemple). L’article relève des noms des personnes traduits par des mois de l’année, des erreurs sur les dates, des pronoms mélangés, etc.). Ces erreurs conduisent à des refus infondés aux conséquences désastreuses pour les demandeurs d’asile.
Depuis 2022, l’optimisme est au plus haut
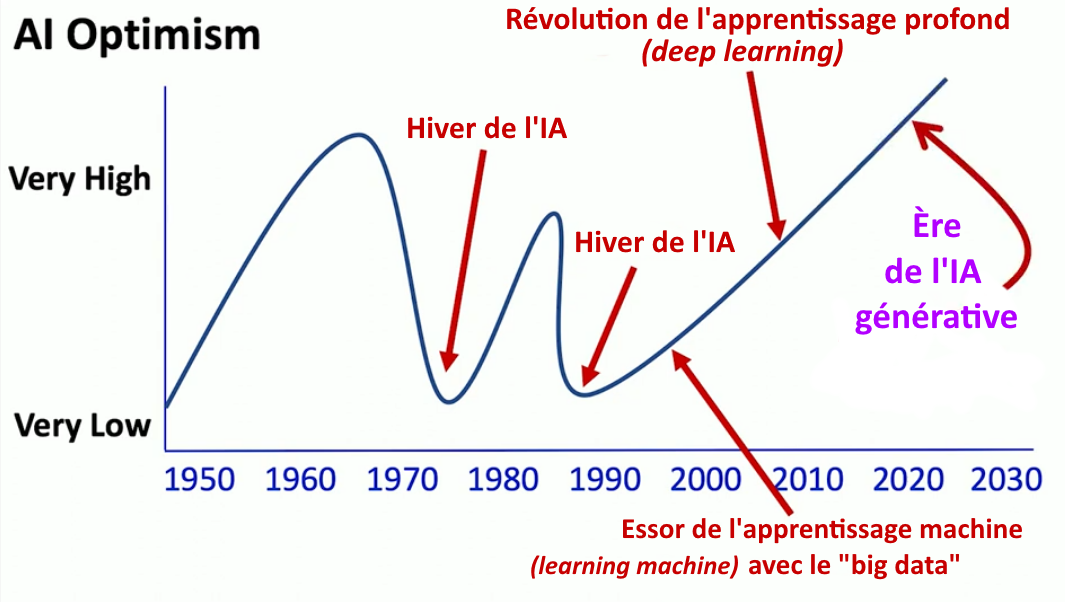
Malgré ces problèmes de compréhension et de robustesse qui affectent l’apprentissage profond, nous sommes aujourd’hui dans une nouvelle ère euphorique, l’ère des IA génératives comme ChatGPT, qui ont fait monter en flèche l’optimisme… jusqu’à crever le plafond. Et toute la question est de savoir si cela va continuer à monter… ou bien si l’IA connaîtra bientôt un nouvel hiver.
FIN DE LA PREMIÈRE PARTIE DE LA CONFÉRENCE
♦ ♦ ♦
[S.C.] : L’entrainement des « modèles » ou réseaux de neurones en IA
Le concept de modèle est important en IA. Il désigne la structure mathématique du programme qui permet à un système intelligent artificiel d’apprendre à traiter et analyser des données pour une tâche donnée. Un modèle apprend, se forme, lors de la phase d’entraînement. Quand il est formé, il sert à traiter des données. Les modèles utilisés en apprentissage profond sont aussi ce qu’on appelle des réseaux de neurones. Ils sont développés par les chercheurs en collaboration avec des ingénieurs.
ChatGPT d’Open IA, Gemini ou PaLM 2 de Google, LlaMa de Meta, Claude de IA Anthropic, sont tous des modèles de traitement du langage du naturel, c’est-à-dire des programmes informatiques. Il n’y a pas de fantôme dans la machine. Ils reposent sur une architecture particulière (leur structure mathématique), qui diffère de l’architecture des modèles utilisés pour la reconnaissance d’image ou la « vision par ordinateur », les « transformeurs » dont il est question dans la suite de la conférence question, objet du prochain article.
Choix et réglage d’un modèle
Pour développer une application, un ingénieur informaticien sélectionne d’abord le modèle le plus approprié à son objectif : identifier des tumeurs, traduire des textes, générer du code informatique, etc. L’ingénieur affine l’architecture de son modèle (le « réseau ») : quel type de réseau utiliser ? avec combien de couches de neurones ? Il règle les paramètres généraux de son modèle de langage, appelés hyperparamètres : taille du réseau de neurones, nombre de connexions (de « nœuds »), vitesse d’apprentissage. Les hyperparamètres régissent le processus d’entraînement lui-même.
Entraînement d’un modèle
L’ingénieur doit ensuite entrainer le modèle sur un ensemble de données, les exemples d’apprentissage, afin que les signaux d’entrée (une image, un son, un texte) produisent en sortie les réponses attendues (reconnaître des objets, reconnaître des paroles, résumer un texte, etc.). C’est la phase d’entrainement qui est aussi une phase d’ajustement : le modèle ajuste automatiquement ses paramètres pour minimiser peu à peu les erreurs, c’est-à-dire réduire la différence entre la sortie réelle et la sortie attendue. On parle d’apprentissage automatique (machine learning) car la machine est programmée pour apprendre d’elle-même, s’auto-corriger.
Comment se fait l’apprentissage lors de l’entraînement ?
L’entrainement d’un réseau ou modèle implique plusieurs processus qui se répètent jusqu’à ce que ses performances atteignent un niveau satisfaisant.
1. La propagation avant de l’information de la couche d’entrée vers la couche de sortie (le feedforward). Chaque neurone reçoit en entrée les sorties des neurones situés en amont et auxquels il est connecté. Chaque connexion a un poids (un coefficient numérique, une certaine valeur). Un “neurone” calcule la moyenne des valeurs qu’il reçoit compte-tenu de la pondération de chacune. La somme pondérée ainsi calculée détermine s’il sera ou non activé, c’est-à-dire s’il transmettra (ou pas) l’information vers les neurones de la couche suivante. Si l’information contribue à la « bonne réponse » (la sortie attendue), le neurone s’active et envoie le signal vers l’avant. Sinon, il ne s’active pas. Ce processus se répète de couche en couche jusqu’à la couche de sortie finale (qui donne la “réponse” du système).
2. Le calcul de l’erreur : la sortie réelle du réseau est comparée à la sortie attendue (contenue dans base des données d’entraînement). Leur différence définit l’erreur (la perte), qui est calculée par une fonction (dite de « perte » ou « de coût »).
3. La rétropropagation (backpropagation) désigne le processus de transmission vers les couches en amont et à travers tout le réseau de l’erreur, ou plus exactement l’information sur le taux d’erreur calculée par la fonction de perte. C’est ainsi que le système apprend, s’autocorrige : l’algorithme de rétropropagation13 modifie automatiquement le « poids » des connexions, diminuant l’influence des unités qui augmentent l’erreur, augmentant à l’inverse l’influence des connexions qui la diminuent.
Supposons un modèle de réseau neuronal pour prédire si un e-mail est ou n’est pas un spam. En entrée, le modèle capturera diverses caractéristiques de l’e-mail (présence de certains mots-clés, longueur de l’e-mail, etc.) – c’est la fonction des « neurones ». Chaque caractéristique est associée à un poids qui représente sa contribution à la prédiction finale, son influence sur le résultat. Le poids d’un indicateur fort de spam (le mot « gratuit » par exemple) sera élevé ; le poids d’un indicateur plus faiblement prédictif d’un spam (la longueur de l’e-mail par l’exemple) sera plus faible, voire négligeable (comme la police d’écriture).
Notion de somme pondérée. Une analogie pour les enseignants, le baccalauréat. Chaque discipline représente un neurone (une unité de calcul) en amont de l’unité finale qui décidera (sortie binaire) si un élève a réussi (1) ou échoué (0). Les unités ou neurones en amont de l’unité finale reçoivent elles-mêmes en entrée des données brutes - la prestation multiforme de l’élève ; puis elles calculent sa note qui devient la valeur transmise à l’unité finale. Mais au baccalauréat, toutes les unités (les disciplines) intervenant dans le calcul final n’ont pas le même poids (coefficient). L’unité finale calcule une moyenne pondérée, c’est-à-dire la somme des valeurs reçues (les notes) compte-tenu de leur pondération (le coefficient disciplinaire). On pourrait imaginer un algorithme correctif modifiant automatiquement les coefficients disciplinaires (les poids, les paramètres du réseau), de façon à toujours obtenir un certain taux d’élèves reçus. Mais ce serait illégal : le poids des disciplines est défini par la loi. En revanche, il existe des algorithmes de modification automatique des notes, qui servent à aligner la moyenne des divers jurys (mais sur quoi ? et selon quelle alchimie ?). Il suffit à un superviseur d’appuyer sur un bouton. Des applications de ce genre ne relèvent toutefois pas de l’apprentissage profond, mes méthodes de programmation classique suffisent.
Pendant l’entraînement, le modèle apprend donc à attribuer l’importance appropriée aux divers paramètres qui capturent tel ou tel aspect des données, il les « modélise », c’est-à-dire crée ainsi une représentation de la structure cachée des données (de leurs caractéristiques et de leurs relations). Cette représentation structurée des données s’appelle un « modèle des données ».
En IA, le terme modèle est ainsi utilisé pour deux choses différentes : pour désigner l’algorithme d’apprentissage (usage le plus fréquent) et le résultat de son application à des données. On pourra dire qu’un modèle (le programme) est utilisé pour traiter des données, pour en construire une représentation appelée modèle de données.
C’est par cette série d’opérations, réitérées autant de fois qu’il le faut, que le modèle (le programme) s’ajuste, c’est-à-dire améliore sa capacité à faire des prédictions précises (c’est un spam / ce n’est pas un spam) et à prendre des « décisions » (le classer dans le dossier des indésirables ou pas). Quand le taux d’erreur est minimal, on considère que le modèle est formé, l’entrainement est alors terminé.
La capacité à traiter des données nouvelles, à généraliser à certain degré, fait la supériorité du machine learning sur les méthodes traditionnelles de l’IA classique.
♦ ♦ ♦
[S.C.] Petit aperçu sur IA, apprentissage automatique, apprentissage profond et IA générative
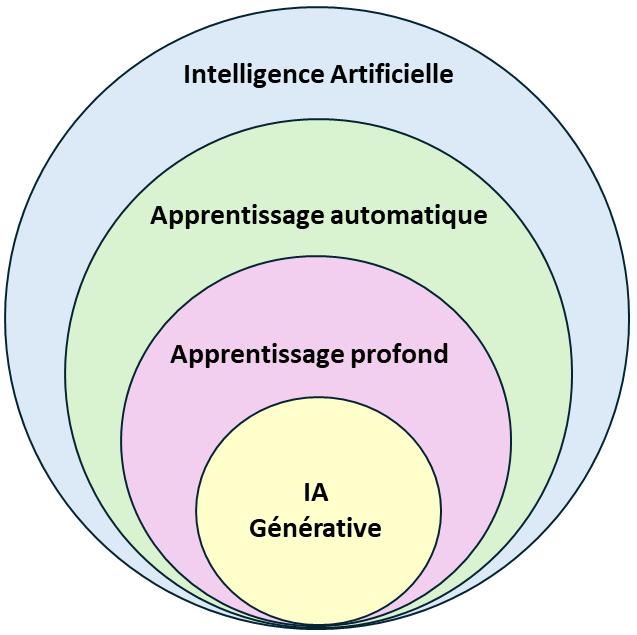
L’intelligence artificielle. L’IA englobe les technologies permettant de créer des systèmes capables d’apprendre, d’analyser des données, de résoudre des problèmes complexes, de faire des prédictions et de prendre des décisions d’une manière qui s’apparente à l’intelligence humains.
L’apprentissage automatique (machine learning) est un sous-domaine de l’IA qui utilise des algorithmes permettant de traiter de grands ensembles de données, exploit auparavant irréalisable. Ces systèmes sont capables d’analyser la structure (le « modèle », pattern) d’un ensemble de données, d’apprendre et de « s’adapter » à des données nouvelles. Ils supposent une intervention humaine importante dans la phase d’entrainement du système.
L’apprentissage profond (deep learning) est un sous-domaine de l’apprentissage automatique. L’apprentissage profond se distingue de l’apprentissage automatique classique par le recours à des réseaux de neurones plus grands (plusieurs dizaines de couches), les « réseaux de neurones profonds » (deep neural networks). Cette différence les rend beaucoup plus performants. \
- Ils sont capables apprendre automatiquement des caractéristiques à partir des données brutes, alors que l’apprentissage automatique suppose un travail assez long de préparation des données, de « nettoyage », de structuration des données pour rendre le traitement plus efficace.
- Ils sont capables de traiter des ensembles encore plus volumineux de données (le big data, les mégadonnées).
- Ils sont capables de modéliser les relations très complexes entre les données. Ce qui leur permet de traiter des tâches elles-mêmes complexes, impliquant des données en très grand nombre, comme la vision par ordinateur, la reconnaissance vocale, et le traitement du langage naturel.
L’IA générative (generative AI) est un sous-domaine de l’apprentissage profond qui repose sur un algorithme d’apprentissage particulier, le « transformeur » (présenté dans la deuxième partie de la conférence). Entraînées sur des ensembles gigantesques de données, les IA génératives sont capables de produire de manière autonome de nouveaux contenus (nouveaux textes, nouvelles images, etc.). Leurs applications sont très larges allant de la génération de texte, de code informatique, à la traduction multilingue et la création de contenus créatifs (en musique, en art), la création d’agents conversationnels (les chatbots) capables de converser avec les êtres humains.
♦ ♦ ♦
Notes
-
Elle avait en fait été précédée une étude de l’université de Stanford, de Washington et de Baidu (le géant chinois d’Internet) dont les résultats ont été rendu publics dès août 2016 par une vidéo sur le site Stanford Univ. Elle comparait les performances en anglais et en chinois mandarin entre la transcription automatisée par dictée et la saisie humaine par les claviers intégrés aux smartphones et constate la supériorité en vitesse des systèmes d’IA, non sans souligner les limites dont un taux d’erreurs corrigées dans le texte transcrit final meilleur chez l’humain. ↩︎
-
J. Despres. Scenario: Shane Legg. Future, 2008. « Human level AI will be passed in the mid 2020’s ». ↩︎
-
« Future Progress in Artificial Intelligence: A Survey of Expert Opinion » repris dans Vincent C. Müller (ed.), Fundamental Issues of Artificial Intelligence, Cham: Springer, 2016, pages 553-571. ↩︎
-
H. McCracken. Inside Mark Zuckerberg’s bold plan for the future of Facebook. Fast Company, 2015 ↩︎
-
S. Russell. Human Compatible: Artificial Intelligence and the Problem of Control. Penguin, p. 77, 2019. ↩︎
-
Sam Altman « they will do almost everything, including making new scientific discoveries that will expand our concept of “everything.” » (Moore’s Law for Everything, 2021) ↩︎
-
Sur les différents niveaux de conduite autonome, cf. sur Wikipédia Niveau d’autonomie d’un véhicule automobile. ↩︎
-
Cf. Yann Le Cun, ouvrage cité, section « L’architecture des grandes applications : l’imagerie médicale et la médecine » dans le chapitre 7 « Dans le ventre de la machine ou le deep learning aujourd’hui ». ↩︎
-
Une étude plus complète de 2023 montre qu’il y a de nombreux biais possibles : « Les images dermatoscopiques et les images cliniques présentent des profils uniques de signaux potentiels pour l’entraînement des systèmes d’IA : par exemple, les images dermatoscopiques révèlent mieux les détails fins d’une lésion, tels que les motifs de pigmentation, et présentent des artefacts particuliers, tels que des marques de règles ou des coins sombres ; les images cliniques peuvent également fournir plus d’informations sur le contexte d’une lésion » (Alex J. DeGrave et alii, Dissection of medical AI reasoning processes via physician and generative-AI collaboration, 2023) ↩︎
-
Ces contre-épreuves suivent le principe le principe des « attaques adversiales » (adversial attacks), une technique qui consiste à modifier les données d’apprentissage d’un modèle soit de façon malveillante pour l’altérer, le corrompre, ou contourner ses restrictions (sécurité), soit dans un but scientifique, pour tester sa robustesse. Voir par exemple : Deep neural network or dermatologist ? (2019). ↩︎
-
L’erreur en question ici, connue des spécialistes de l’IA, est due au phénomène « surajustement » (overfitting) - ou sur-apprentissage. Le système s’est sur-adapté aux données d’entrainement, au point de prendre en compte des caractéristiques qui ne sont pas liées au problème et constituent simplement du « bruit » (comme on parle de bruit de fond pour un signal audio, c’est-à-dire de signaux parasites à ignorer). Les hyperparamètres d’un système permettent de régler ce phénomène. ↩︎
-
Pour une explication intuitive, pédagogique et drôle de ce fameux algorithme, cf. « La rétropropagation expliquée à ma Tata » (2022) d’Hervé Rincent, ingénieur en informatique.. Il s’agit en fait d’un algorithme de correction des erreurs dit « algorithme de rétropropagation du gradient » parce qu’il repose sur le calcul du « gradient » de l’erreur, c’est-à-dire du « taux de variation » d’une fonction qui mesure l’erreur (la « fonction de perte » ou « de coût »). Lors de la phase d’apprentissage du modèle, la fonction de perte quantifie l’écart entre ses prédictions (ses « sorties ») et les sorties attendues. On parle aussi d’algorithme de « descente du gradient » car il s’agit de minimiser la valeur de cet écart, de minimiser l’erreur. Pour en savoir plus sur ce point, voir Yann Le Cun, Quand la machine apprend. La révolution des neurones artificiels et de l’apprentissage profond, chapitre 4 « Apprentissage par minimisation, théorie de l’apprentissage ». ↩︎