
Melanie Mitchell, © Quanta Magazine qui lui consacre un excellent article
Dans l’article précédent, Comment s’orienter dans les discussions sur l’intelligence artificielle ?, j’ai indiqué quelques livres d’introduction générale à l’IA et aux questions qu’elle soulève. J’ai regretté le manque d’ouvrages généraux (en français) traitant de la révolution introduite par les IA génératives du type ChatGPT et de leur fonctionnement. Nous ne sommes pas pour autant sans ressources. Pour introduire à l’IA, j’ai conseillé la lecture d’Intelligence artificielle. Triomphes et déceptions de la chercheuse et spécialiste Melanie Mitchell. Elle a donné récemment une conférence The Future of Artificial Intelligence qui intègre la question des IA génératives. Il en existe au moins deux versions en ligne, la première du 16 novembre 2023 au Santa Fe Institute où elle enseigne, la seconde de mars 2024 à l’Université de Californie à Davis.
Cette conférence est vraiment bien faite, elle couvre l’histoire de l’IA jusqu’à aujourd’hui, donne juste ce qu’il faut d’explication technique et aborde des problèmes cruciaux. Mais elle est en anglais, ce qui peut être un obstacle pour un public déjà non spécialiste de l’IA et de plus francophone. J’ai projeté d’en faire une adaptation écrite et demandé son accord à Melanie Mitchell. Ce qu’elle a fait immédiatement et je l’en remercie vivement.
À la différence des entretiens de Jacques Bouveresse, la transcription quasi littérale de sa conférence abondamment illustrée d’images aurait été sans intérêt. C’est donc une adaptation : j’ai suivi son plan et reformulé le contenu, adapté la plupart des diapos en français. Je reste toujours au plus près du propos de Melanie Mitchell. Dans une perspective pédagogique, j’ai précisé ou complété des références, parfois ajouté un commentaire explicatif toujours signalé par [S.C].
La conférence est en trois parties
I. Le passé chaotique de l’intelligence artificielle (en deux articles).
Le passé chaotique (1)
Le passé chaotique (2)
II. Un présent déroutant, à la fois étonnant, porteur d’espoirs et de craintes (en deux articles).
Un présent déroutant (1)
Un présent déroutant (2)
III. Un avenir radicalement incertain
♦ ♦ ♦
I. Le passé chaotique de l’intelligence artificielle. (1)
Résumé. Depuis ses débuts dans les années 1950, le domaine de l’intelligence artificielle a alterné à plusieurs reprises entre des périodes d’optimisme exagéré (les « printemps de l’IA ») et des périodes de déception et de perte de confiance (les « hivers de l’IA »). Nous sommes de nouveau dans une phase d’exaltation depuis l’arrivée de ChatGPT et des IA génératives
Introduction : qu’est-ce que l’intelligence artificielle ?
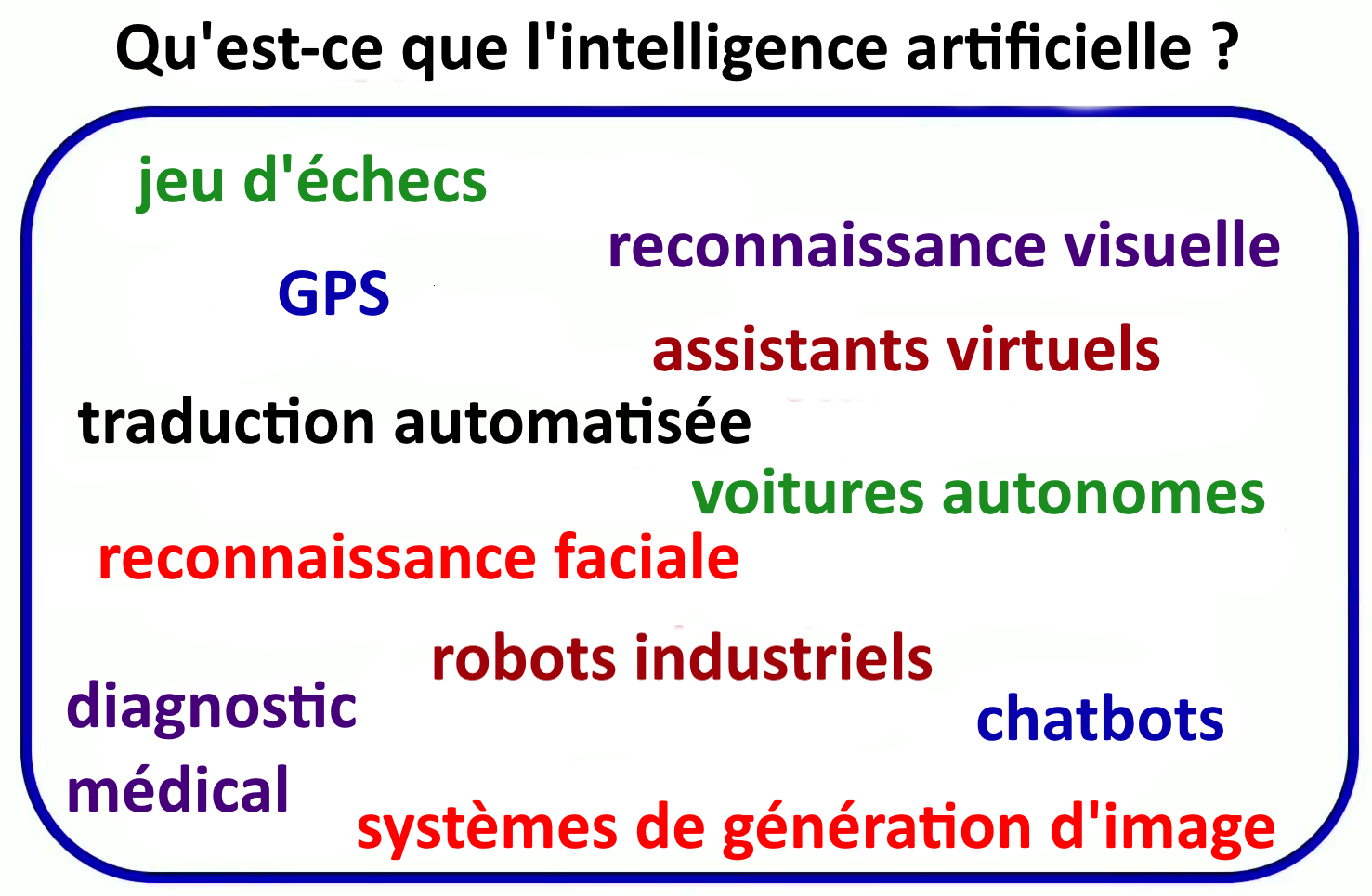
L’expression Intelligence Artificielle renvoie à une diversité d’applications pratiques d’usage plus ou moins courants : jeux d’échecs électroniques, GPS, traducteur, programme de diagnostic médical, de reconnaissance vocale ou faciale, voitures autonomes, robots industriels, et agents conversationnels [chabots].
Mais l’IA est d’abord une entreprise théorique, scientifique et philosophique, a pour l’objectif de comprendre les mécanismes de l’intelligence humaine, de faire des machines capables de les reproduire et aussi de les comparer pour mieux comprendre ce que c’est que d’être humain.
Au fil du temps, les recherches en IA ont changé notre vision de l’intelligence humaine et de ce qui fait sa spécificité. Par exemple, dans l’imaginaire collectif, le jeu d’échecs représentait la forme supérieure de l’intelligence humaine, celle qu’aucune machine ne pourrait égaler jusqu’à ce que l’ordinateur Deep Blue d’IBM batte en 1997 le meilleur du monde (Garry Kasparov), à la stupéfaction générale. L’orgueil humain venait d’en prendre un coup. Mais cela a surtout entrainé une modification de notre compréhension de l’intelligence humaine et de celle des machines : battre l’humain aux échecs n’était pas finalement pas une preuve d’intelligence.
Le développement de l’IA soulève des questions cruciales pour l’avenir : Est-ce que l’IA augmentera considérablement la productivité humaine ? Est-ce que l’IA révolutionnera la médecine, la justice, la recherche scientifique ? Est-ce que l’IA deviendra plus intelligente, plus performante, que les humains dans toutes les tâches cognitives ? Est-ce que l’IA remplacera l’humain dans beaucoup métiers ? Est-ce que l’IA détruira la démocratie ? Est-ce que l’IA provoquera l’extinction de l’humanité ?
Beaucoup d’entre nous se posent ces questions. Certains font des prédictions très assurées alors qu’il est très difficile d’y répondre, comme on le verra.
♦ ♦ ♦
Naissance l’intelligence artificielle (1955)

© Rockefeller Foundation (doc. p.11 et suiv.)
On peut considérer que l’IA a véritablement commence l’été 1955, au Darmouth College (New Hampshire, États-Unis), quand un groupe de mathématiciens et d’ingénieurs éminents proposent un séminaire de recherche sur l’intelligence artificielle1.
L’expression intelligence artificielle est due à McCarthy qui voulait distinguer cette discipline des recherches connexes regroupées sous le nom de cybernétique2

© Rockefeller Foundation (idem)
« Nous proposons de conduire une étude de 2 mois, réunissant 10 hommes et traitant de l’intelligence artificielle durant l’été 1956 (…) L’étude doit se fonder sur la conjecture selon laquelle chaque aspect de l’apprentissage ou de toute autre caractéristique de l’intelligence pourrait être décrit si précisément qu’une machine pourrait être fabriquée pour la simuler. »
« Nous pensons qu’un progrès significatif peut être fait dans la résolution d’un ou plusieurs de ces problèmes, si un groupe de scientifiques soigneusement sélectionnés y travaillent ensemble durant un été ».
Les chercheurs mentionnent un certain nombre de pistes incluant la conception de nouveaux langages de programmation, l’étude des performances des algorithmes, l’utilisation de réseaux de neurones simulés, l’analyse et la simulation de la créativité, l’étude des phénomènes d’abstractions, de conceptualisations, la mise en œuvre de mécanismes d’auto-apprentissage pour rendre les machines capables d’améliorer elles-mêmes leur fonctionnement. L’IA comme discipline scientifique repose sur une conjecture : toutes les fonctions cognitives peuvent être décrites avec une précision telle qu’il serait possible de programmer un ordinateur pour les reproduire.
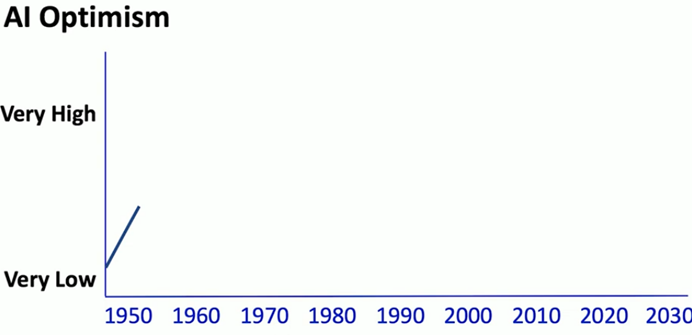
En 1955, l’optimiste sur concernant l’avenir de l’IA est assez élevé.
Si on veut représenter de façon approximative l’optimisme au sujet de l’IA dans les années 50, on aurait quelque chose comme cela :
Le projet se réalisera l’année suivante lors d’une université d’été (du 18 juin au 17 août) organisée par John McCarthy (fondateur su laboratoire d’intelligence artificielle de l’université Stanford), Marvin Minsky (fondateur du laboratoire d’IA du MIT), tous les deux mathématiciens et informaticiens, Nathaniel Rochester (pionnier du génie électrique, architecte en chef de l’IBM 701, premier gros ordinateurs produit en série) et Claude Shannon (mathématicien, fondateur de la théorie de l’information).
Franck Rosenblatt et le Perceptron
L’optimisme va augmenter avec les travaux du psychologue Frank Rosenblatt pour simuler par un programme informatique le fonctionnement d’un réseau de neurones du cerveau humain, qui aboutiront à la fabrication en 1957 d’une machine à un « neurone » (ou monocouche) doté de multiples entrées numériques et d’une seule sortie, le Perceptron Mark 1.
[S.C.] Le perceptron inventé par Frank Rosenblatt est un algorithme d’apprentissage automatique de reconnaissance de caractères alphanumériques qui simule le fonctionnement des neurones du cerveau. Il jette les bases du courant neuronal à l’origine des réseaux neurones modernes sur lesquels repose en grande partie l’IA aujourd’hui. Tous les spécialistes commencent par Rosenblatt et son perceptron car il permet d’exposer des concepts fondamentaux de l’approche neuronale en IA (appelée aussi neurocalcul, IA sub-symbolique ou IA non-symbolique – cf. note 8).
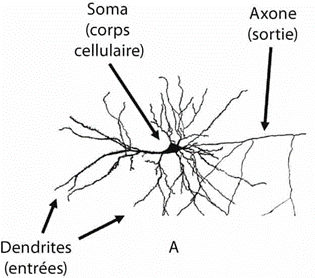
Pour comprendre l’analogie : un neurone (figure A) est une cellule cérébrale (le cerveau humain en comprend 86 milliards interconnectées). Il reçoit en entrée des informations des autres neurones sous forme de signaux chimiques par l’intermédiaire des dendrites qui sont des prolongements du corps cellulaire (soma) provenant des neurones. La synapse désigne la zone fonctionnelle de contact entre deux neurones.
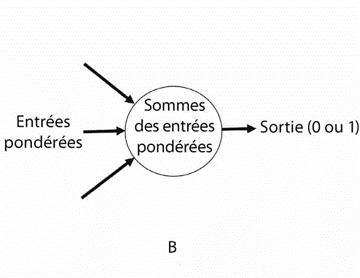
La figure B représente un neurone simulé (le perceptron par exemple). Principe : un neurone (biologique ou simulé) « calcule » la somme des entrées qu’il reçoit des autres neurones et si cette somme atteint un certain seuil, il se déclenche (c’est l’activation). Les connexions (synapses) reliant différents neurones à un neurone donné ont des « poids » différents : la somme des entrées tient compte du « poids » respectif de chaque connexion : certaines « pèsent plus lourd » (valeur ou importance supérieure) pour l’activation du neurone, c’est-à-dire la production d’un signal en sortie. Les neurobiologistes pensent que l’ajustement du « poids » des connexions entre neurones constitue un élément clé du sous-bassement neuronal de l’apprentissage. L’apprentissage renforcerait certaines liaisons synaptiques ou les stabiliserait, et en affaiblirait ou supprimerait d’autres (elles seraient « élaguées » 3).
(Illustrations : Melanie Mitchell, Intelligence artificielle. Triomphes et déceptions_, p. 18. Voir la section pages 24-34 pour le principe de fonctionnement d’un perceptron, son intérêt, ses utilisations et ses limites_).
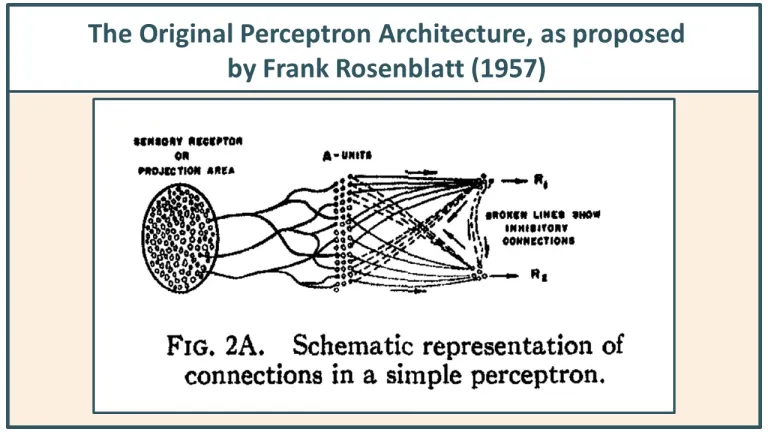
Dessin original du Perceptron par Rosenblatt (1957)
Franck Rosenblatt pensait donc que le traitement de l’information par les neurones pouvait être simulé par un programme informatique – le perceptron – doté de multiples entrées numériques et d’une seule sortie.
[S.C.] L’analogie entre neurone et programme informatique date des premiers automates proposés en 1943 par Warren McCulloch et Walter Pitts (neuroscientistes et cybernéticiens) qui considèrent les fonctions de l’esprit comme des fonctions mathématiques (un opérateur transformant des entrées en sorties) et proposent le premier modèle de neurone simulé (c’est-à-dire la première représentation mathématique d’un neurone biologique). C’est un neurone simulé binaire et sa sortie (qui vaut 0 ou 1, ou -1 et 1 selon les conventions) est la somme pondérée de ses entrées. Quand cette somme pondérée dépasse une certaine valeur (le seuil d’activation), le neurone simulé est activé (sa sortie est 1), sinon elle vaut 0 (ou -1).

© R. Hecht-Nielsen Perceptrons. Technical report.
Rosenblatt photographié avec « l’œil » (un réseau de photoconducteurs de 20 x 20) du « neuro-ordinateur » de reconnaissance de formes Perceptron Mark I. Le faisceau de 400 fils devant Rosenblatt constitue le « nerf optique » du système visuel du perceptron. Le Perceptron de Frank Rosenblatt sert d’abord à reconnaître des lettres. Il se présente comme une grosse armoire métallique d’où s’échappent des milliers de fils électriques. Il associe des cellules photoélectriques qui captent une image d’entrée (comme une rétine) et des centaines de boutons permettant d’ajuster les « poids ».4 Mais l’innovation majeure du perceptron est que lors de la phase d’apprentissage par essai / erreur, il ajuste automatiquement ses poids après chaque présentation d’une image et de la sortie désirée correspondante qui est présentée par l’opérateur5 durant ce qu’on appelle la phase d’entraînement. Quand il n’y a plus d’erreur dans les « réponses » (ici reconnaître correctement une lettre de l’alphabet), l’entraînement est terminé et la machine est prête pour l’usage prévu.

© R. Hecht-Nielsen Perceptrons. Technical report.
Sur la photo on voit l’ingénieur Charles Wightman, collègue de Rosenblatt, effectuer un réglage du Perceptron Mark I. Les liasses de fils au premier plan se trouve au niveau des baies de brassage où se font les connexions électriques. Au début de l’entraînement le poids des connexions est fixé de façon aléatoire. Le fait qu’ensuite le système puisse apprendre à reconnaître correctement les caractères par ajustement de ses paramètres était la preuve pour les chercheurs que l’on était très proche d’arriver à simuler le cerveau. Contrairement ce que pourrait laisser croire la photo (les milliers de fils et les boutons), ce qu’on appelle réseau neuronal en informatique n’est pas la structure matérielle mais logicielle, c’est-à-dire un programme informatique (un ensemble d’équations mathématiques).
Les prédictions très optimistes de Rosenblatt et des autres chercheurs

Le fait que le perceptron était capable d’apprendre de manière adaptative des tâches perceptives relativement simples était une propriété très étonnante. Elle suscitait de l’enthousiasme et surtout de grands espoirs. Rosenblatt lui-même était très optimiste, comme en témoigne sa conférence de presse de 1958 donnée conjointement avec la Marine (qui finançait ses recherches) et rapportée par le New York Times :
« La Marine a révélé aujourd’hui l’existence d’un embryon d’ordinateur électronique qui pourra, selon elle, marcher, parler, voir, écrire, se reproduire et être conscient de son existence. »
« Selon certaines prédictions, les futurs perceptrons seront capables de reconnaître des personnes, de dire leurs noms et de traduire instantanément, oralement ou par écrit, les paroles d’une langue dans une autre langue. »
« M. Rosenblatt a déclaré qu’en principe, il serait possible de construire des cerveaux qui pourraient se reproduire à la chaîne et qui seraient conscients de leur existence. »
Le phénomène d’emballement médiatique et d’annonces fracassantes autour l’IA ne date pas d’aujourd’hui.
L’optimisme croit encore…

L’optimisme s’accroit considérablement et le retentissement très large des travaux de Rosenblatt engendre dans la presse et chez certains chercheurs une confiance irrationnelle dans le progrès très rapide des réseaux neuronaux et la création d’une intelligence artificielle simulant la pensée humaine. Les annonces spectaculaires de 1958 sont en effet rapidement suivies de proclamations similaires par les pionniers de l’IA. Leur confiance est si élevée que les chercheurs en sciences cognitives A. Newell et H. A. Simon projettent en 1961 de construire un « programme de résolution de problème » (General Solver Problem, à ne pas confondre avec le GPS d’assistance à la conduite) qui simulera la pensée humaine » 6. On peut considérer le General Problem Solver comme le premier projet d’intelligence artificielle générale. Son approche relève de l’IA symbolique promise alors à un bel avenir alors que l’approche neuronale sous-tendant le perceptron allait bientôt décliner.

Claude Shannon, l’inventeur de la théorie de l’information, donne la mesure de l’optimisme des pionniers quand, en 1961, il se déclare convaincu que « d’ici 10 ou 15 ans » des robots proches de ceux popularisés par la science-fiction sortiront des laboratoires. »7

En 1965 ([S.C.] plutôt 19608) Herbert Simon (prix Nobel d’économie) prédit que d’ici une génération les machines seront capables d’effectuer n’importe quel travail fait par un être humain
[S.C.] : avec toutefois une réserve pour certains emplois qui se confirme aujourd’hui pour l’artisanat et les métiers de service à la personne « Technologiquement, comme je l’ai dit plus tôt, les machines seront capables, d’ici vingt ans, de faire n’importe quel travail qu’un homme peut faire. Sur le plan économique, les hommes conserveront un avantage comparatif plus grand dans les emplois qui exigent une manipulation fine des éléments d’un environnement relativement complexe – comme certaines formes de travail artisanal, le contrôle de certains types de machines (par exemple, la conduite d’engin de terrassement), certains types de résolution de problèmes non programmés et certains types d’activités de service où l’interaction humaine face à face est essentielle. » 9

En 1967, Marvin Minsky (co-organisateur avec John McCarthy de la fameuse de conférence de Dartmouth) affirme que « d’ici une génération, les problèmes posés par la création d’une “intelligence artificielle” seront en grande partie résolus »10. Tous ces chercheurs pensaient que l’intelligence artificielle atteindrait rapidement le niveau de l’intelligence humaine — c’est-à-dire le niveau d’une intelligence générale et l’optimisme était au plus haut.
[S.C] Sur IA Symbolique et IA sub-symbolique (neuro calcul)
Dans son livre, Melanie Mitchell explique la différence entre ces deux paradigmes (l’IA symbolique et l’IA sub-symbolique ou approche neuronale) à partir de ces deux innovations le : General Problem Solver et le Perceptron.
L’IA symbolique cherche à comprendre et à reproduire la dynamique des pensées, en prenant pour unité élémentaire des propositions simples, qui sont ensuite manipulées selon des règles formelles. Un programme d’IA symbolique est aisément compréhensible par un humain car il se compose généralement de symboles (au sens de la logique formelle) et de règles logiques élémentaires qui permettent de combiner ces symboles pour effectuer une certaine tâche (exemple : If number = 1 Then GoTo Line1 Else GoTo Line2). Pour imiter les fonctions cognitives du cerveau, on ne cherche pas le fonctionnement neuronal du cerveau.
A l’inverse, l’idée qui fonde l’IA sub-symbolique (l’approche neuronale) est qu’il faut s’inspirer du fonctionnement biologique pour arriver à faire une machine capable de reproduire les fonctions cognitives (par exemple, la vision avec le perceptron). Un programme d’IA sub-symbolique est loin du langage naturel donc moins lisible parce qu’il est composé d’un empilement d’équations mathématiques formant « un maquis d’opérations sur des nombres, souvent difficiles à interpréter »11.
Autre différence : l’IA symbolique se veut générale (on cherche à programmer la machine pour qu’elle sache raisonner ou résoudre des problèmes dans différent domaines. L’approche neuronale vise à reproduire le fonctionnement d’unités neuronales impliquées dans des tâches spécialisées comme la perception de formes ou la reconnaissance d’objets (pour un exposé consistant sur ces deux paradigmes constitutifs du domaine de l’IA, cf. Daniel Andler12).
Le premier hiver de l’IA
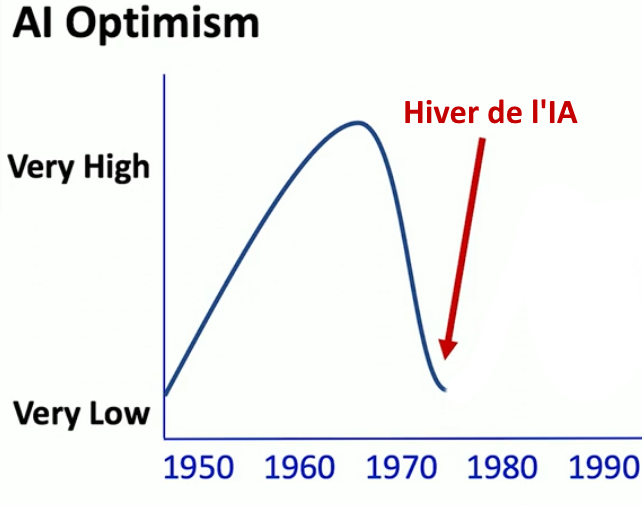
Les choses ne se sont pas passées comme les pionniers l’avaient prévu : faire des machines intelligentes s’est avéré plus difficile qu’ils ne le pensaient. En 1969, Marvin Minsky (pourtant optimiste au départ !) et Seymour Papert montrent que les types de problèmes pouvant être résolus par les perceptrons de Rosenblatt sont très limités et jugent l’approche neuronale sans avenir13. À l’optimisme exubérant des débuts (ce qu’on appelle le « printemps de l’IA ») succède un pessimisme radical, c’est le premier « hiver de l’IA ». Comme les attentes sont déçues, l’IA tombe en disgrâce. Les investissements publics et privés se tarissent : plus d’argent, plus de recherche.
Nouveau printemps…
Mais la situation va bientôt s’améliorer et l’optimisme des chercheurs revenir avec le développement des « systèmes experts », c’est-à-dire de programmes capables d’exécuter des tâches d’expertise (donc « intelligentes ») comme faire un diagnostic médical, une expertise judiciaire, etc.
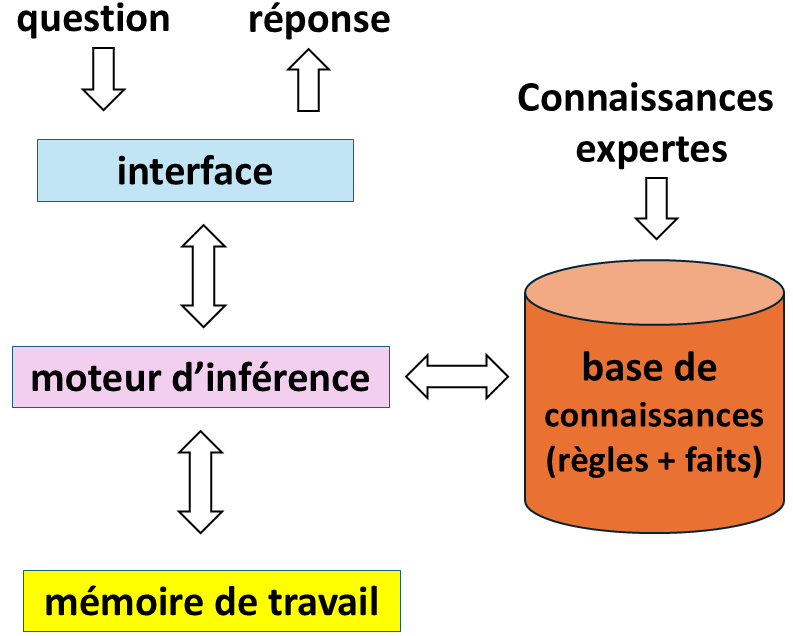
Dans les systèmes experts toute la « connaissance » est programmée « à la main ». Les informaticiens recueillent d’abord cette connaissance auprès des experts, c’est-à-dire les faits (les cas traités et leurs caractéristiques) ainsi que les règles qu’ils suivent pour prendre une décision (si X, alors Y ; sinon, Z). Ces connaissances sont ensuite encodées dans la machine.
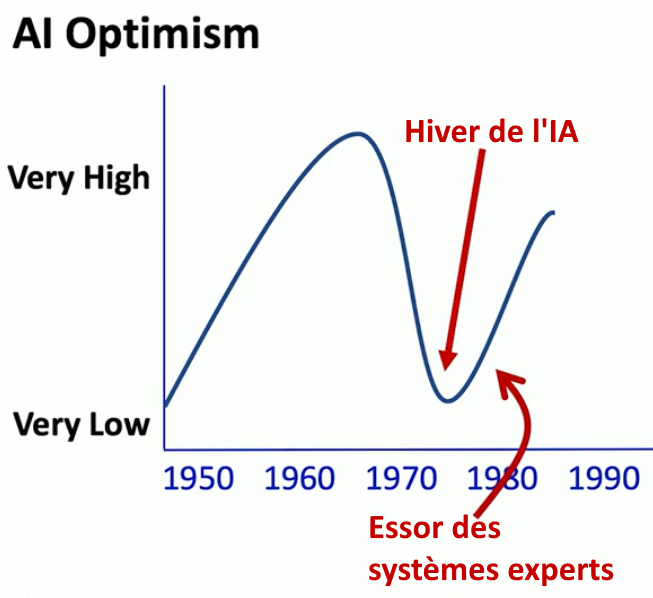
[S.C.] Les systèmes experts reposent sur l’IA symbolique (cf. plus haut et note 15), c’est-à-dire l’idée que l’on peut formaliser de façon symbolique « l’intelligence humaine ». Les années 80 sont celles de la montée en puissance des systèmes experts (DENDRAL en chimie, MYCIN en médecine, PROSPECTOR en géologie). Là encore l’optimisme est de rigueur et certains annoncent déjà que l’on pourra capturer toutes les connaissances de tous les métiers et fabriquer autant de « systèmes experts » qui remplaceront bientôt les médecins, les avocats, les ingénieurs logiciel, etc. L’IA égalera et même surpassera le niveau d’expertise de l’intelligence humaine. L’optimisme est reparti.

[S.C.] Sur ce point, voir sur microship.com la reproduction de l’article (en anglais) de Steven K. Roberts, très représentatif de la période, Les ordinateurs simulent des experts humains (Mini-Micro Systems, September, 1983).
Il débute ainsi : « L’ingénierie de la connaissance répond à des applications précédemment considérées comme impossible à informatiser. La conférence de 1982 de l’ American Association for Artificial Intelligence a démontré que l’intelligence artificielle, un domaine traditionnel de l’Université, commence enfin à attirer l’attention des chefs d’entreprise soucieux de rentabilité. Le pourcentage de participants de l’industrie privée était plus élevé que jamais, et l’exposition comprenait plusieurs produits réels avec des feuilles de spécification et des numéros de modèle. Bien que l’intelligence artificielle soit un domaine diversifié, comprenant le traitement en langage naturel et la vision par ordinateur, la plupart des progrès réalisés en matière d’IA ont été réalisés en utilisant des ordinateurs pour simuler des experts humains dans des sujets étroitement définis. À l’aide d’approches heuristiques et de nouveaux environnements de programmation, ces « systèmes d’experts » constituent une nouvelle classe d’applications informatiques passionnantes et rentables ».
Fin des années 90, nouvel hiver de l’IA
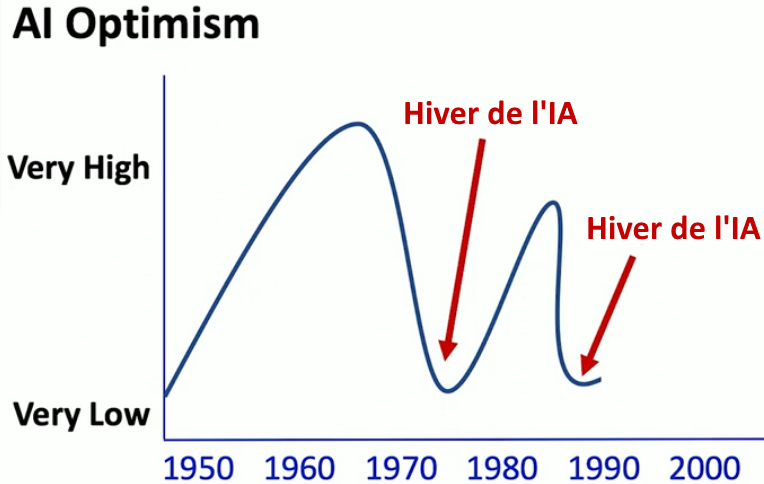
Encore une fois on a crié victoire trop vite. Les systèmes experts vont s’avérer trop rigides, sujets aux erreurs et le plus souvent incapables de généraliser, c’est-à-dire de s’adapter à des situations vraiment nouvelles. Les approches fondées sur l’IA symbolique se révèlent ni aussi utiles ni aussi robustes qu’attendu. Après une période de grandes promesses, d’énormes financements et de battage médiatique, l’IA symbolique sombre dans un autre hiver. (« Lorsque j’ai obtenu mon doctorat en 1990, précise Melanie Mitchell, on m’a conseillé de ne pas utiliser le terme « intelligence artificielle » dans mes demandes d’emploi »).
Ce phénomène est fréquent en technologie, les choses arrivent par cycle. En 1984, Drew McDermott, spécialiste en IA, inquiet de l’optimisme excessif autour des projets de « voiture autonome » décrit ce phénomène de cycles pour mettre en garde contre les effets pervers de l’optimisme exagéré (on lui doit l’expression « hiver de l’IA ») :
« Peut-être que les attentes sont trop élevées, et… Cela finira par entraîner un désastre. Supposons que dans cinq ans, [le financement] s’effondre lamentablement parce que les voitures autonomes ne marchent pas. Les start-ups font faillite. Et il y a un grand contrecoup, de sorte qu’il devient impossible d’obtenir de l’argent pour tout ce qui est lié à l’IA. Tout le monde change à la hâte le nom de ses projets de recherche. Cette situation [est] appelée “l’hiver de l’IA” » (Drew McDermott14)
En d’autres termes, des avancées apparentes conduisent les spécialistes de l’IA à prédire des progrès rapides, une commercialisation prochaine et assurée d’applications nouvelles, l’assurance d’atteindre la « véritable IA » à court terme. Les gouvernements et les entreprises se laissent emporter par l’enthousiasme et financent largement la recherche et le développement. C’est le printemps de l’IA. Lorsque les progrès stagnent, que les attentes sont déçues, l’enthousiasme, le financement et les emplois se tarissaient. L’hiver de l’IA survient ([S.C.] : pour l’analyse de ce phénomène de cycle, voir Melanie Mitchell, Why AI is Harder Than We Think15).
Début des années 2000, regain d’optimisme et nouvel essor de l’IA
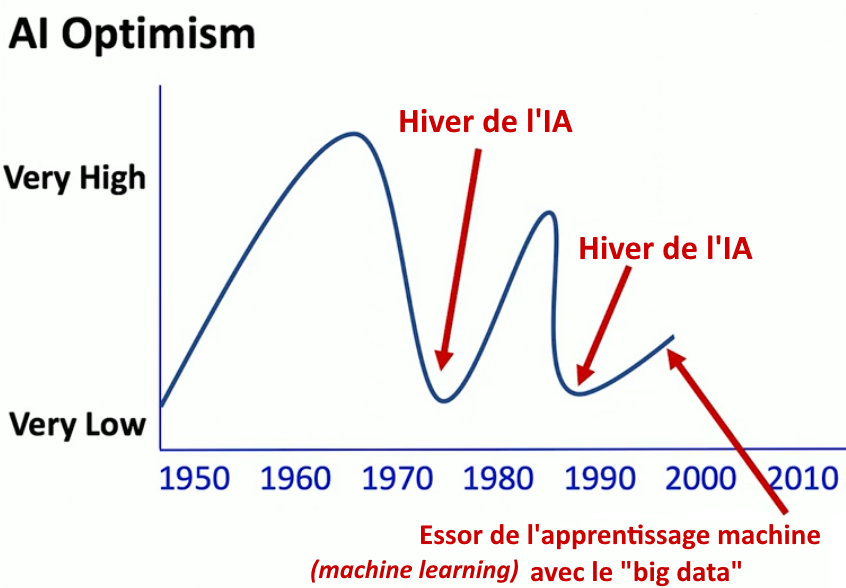
Au tournant des années 2000, l’optimisme revient avec la montée en puissance l’apprentissage automatique (le machine learning) grâce à l’utilisation des « big datas » ou « données de masse », c’est-à-dire des ensembles gigantesques de données numériques. Le big data exigeait le développement de nouveaux algorithmes pour arriver à stocker, classer et analyser de telles quantités de données. La masse de données est en effet telle que qu’elle devient trop complexe à décrire et compte-tenu de toutes les entrées possibles, il devient aussi impossible de programmer leur traitement de manière classique. D’où le retour de l’idée de l’apprentissage automatique avec des réseaux de neurones : plutôt que de programmer le fonctionnement des machines avec des connaissances prédéfinies comme dans la programmation traditionnelle (l’IA classique ou symbolique), essayons de faire en sorte que la machine « découvre » elle-même les règles dont elle a besoin pour exécuter correctement une tâche à partir d’un ensemble de données. On repense alors aux perceptrons « multicouches » dont l’idée étaient abandonnée par les chercheurs, sauf une poignée d’entre eux (dont Yann Le Cun).

Le développement d’Internet dans les années 90 qui a rendu possible l’essor de l’apprentissage machine classique. Le décollage du Web mondial dans les années 2000 des ensembles gigantesques de données sont devenues devenaient soudainement disponibles. Les internautes ont en effet commencé à publier et partager sur Internet des quantités énormes de photos (souvent de chats et de chiens !) et de textes. C’est ainsi que la base de données IMAGENET (1,5 millions d’images annotées par des humains) a pu être créée. Ce sont des données sont annotées c’est-à-dire accompagnées de petite description (« c’est mon chat », « c’est Kiki », « c’est mon bouledogue » …mais aussi « c’est tata Simone », « c’est ma nouvelle voiture », etc.).
C’est donc la conjonction de la disponibilité de ces bases de données énormes (big data) et d’ordinateurs de plus en plus puissants (nécessaires pour effectuer les calculs) qui a permis de développer l’apprentissage automatique (machine learning) et d’entraîner les machines à reconnaître un chien, un chat, ….un être vivant ou un objet quelconque.
♦ ♦ ♦
[S.C.] : une pause avant la suite de cette première partie de la conférence dans le prochain article, pour préciser quelques notions importantes pour comprendre la suite.
Dans le domaine de l’intelligence artificielle, il y a façons de définir les règles et instructions suivies par une machine (un ordinateur) : la programmation traditionnelle, noyau dur de l’IA dans les années 70 et 80 et l’apprentissage automatique (le machine learning) dominant depuis le début des années 2000. Dans la première, l’humain définit toutes les règles et instructions ; dans le second la machine apprend automatiquement les règles, c’est-à-dire à modéliser des données pour faire des prédictions et/ou prendre des décisions.
En programmation traditionnelle, les règles sont définies par les programmeurs disposant d’une connaissance approfondie d’un domaine donné, acquise auprès des experts ou professionnels. Ici l’ingénieur analyse le problème à traiter, identifie les règles nécessaires et écrit le code qui spécifie les étapes exactes que l’ordinateur doit suivre pour accomplir une tâche : résoudre un problème (établir un diagnostic médical par exemple) et prendre une décision (proposer un traitement). Le code (le programme) spécifie comment les données d’entrée doivent être traitées et quelle sortie doit être produite en fonction des conditions prédéfinies et des instructions logiques. Le programme suit précisément ces instructions. C’est l’IA classique ou IA symbolique que ses tenant appellent parfois GOFAI, acronyme de good old-fashioned artificial intelligence, « la bonne vieille intelligence artificielle »).
Toute modification ou mise à jour du programme nécessite une modification manuelle du code. Cette approche fonctionne bien pour les problèmes avec des règles et des solutions claires et bien définies, mais elle s’est avérée insuffisante pour les tâches complexes, impliquant de l’incertitude ou nécessitant que le système s’adapte à de nouvelles données.
En apprentissage automatique (machine learning), plutôt que de tout enseigner à la machine, on cherche à la rendre capable d’ « apprendre » à partir de « l’expérience », c’est-à-dire capable par de découvrir toute seule pour ainsi dire les règles à suivre pour effectuer une tâche donnée. Ici, l’ingénieur doit inventer un modèle algorithmique d’apprentissage automatique qui rende le sytème capable d’améliorer automatiquement ses performances au fil du temps. Une fois le système conçu, l’ingénieur doit l’« entraîner » (c’est l’apprentissage) en le formant grâce à des ensembles énormes de données.
Les modèles d’apprentissage automatique ont donc une certaine capacité à généraliser à partir de leur « expérience » (le jeu des exemples d’apprentissage) pour « prédire » ou « prendre des décisions » quand ils rencontrent des données ou situations nouvelles.
EXEMPLE 1. Admettons que nous devions apprendre à une machine classer des images de chats et de chiens. En programmation traditionnelle, l’ingénieur doit définir les règles ou les caractéristiques spécifiques permettant d’identifier et de distinguer un chat d’un chien (la forme de leurs oreilles, de la truffe, du museau, etc.). Cette approche prend du temps et peut ne pas « capturer » toutes les informations pertinentes.
En apprentissage automatique, la machine est d’abord entraînée à accomplir une tâche à partir d’un vaste ensemble de données – par exemple des images étiquetées, c’est-à-dire où chaque image utilisée en entrée pour l’apprentissage est associée à une description (la classe appropriée : chat ou chien). Pendant la phase d’entrainement, la machine « apprend » à « reconnaître » (extraire automatiquement) les caractéristiques importantes de l’image pour réussir sa classification. Une fois entraîné, le système peut alors prédire à quelle classe appartient une image nouvelle (c’est-à-dire jamais vue lors de l’entraînement).
EXEMPLE 2. Supposons maintenant que nous devions classer des e-mails en spam ou non-spam. En programmation traditionnelle, l’ingénieur définira des règles pour y arriver, par exemple, vérifier la présence de mots-clés spécifiques (« gratuit », « pas de frais », « appelez vite », « vous avez gagné », « cliquez sur ce lien », etc.), ou encore comparer l’adresse de l’expéditeur à une liste de spammeurs recensés, etc. Le programme appliquera ensuite ces règles aux e-mails entrants pour déterminer leur classification.
En apprentissage automatique, l’ingénieur fournira à la machine un très vaste ensemble de données d’e-mails étiquetés « spam » (pourriel) ou « non spam ». Ensuite grâce à son algorithme, la machine « apprendra » toute seule à identifier les caractéristiques des courriels indésirables sur des milliers ou dizaines de milliers d’exemples et fabriquer ses « règles » pour traiter efficacement les spams. Une fois entrainé, son modèle sera capable de classer des e-mails semblables à ceux qu’elle a « vu » en formation mais aussi d’identifier de nouveaux spams à partir du modèle élaboré. Cette faculté de s’adapter à des cas nouveaux fait la force du l’apprentissage automatique.
Notes
-
McCarthy et al., « A Proposal for the Dartmouth Summer Research Project in Artificial Intelligence », 1955, reproduite dans AI Magazine, 27, no 4, 2006, p. 12-14 (pdf). ↩︎
-
Sur ce point et les premiers débuts, cf. Melanie Mitchell, Intelligence artificielle. Triomphes et déceptions, 2021, Dunod, p. 18 et suivantes. ↩︎
-
Cf. « Plasticité cérébrale, de quoi parle-t-on ? » dans Jean-François Dortier éd., Le cerveau et la pensée. Le nouvel âge des sciences cognitives. Éditions Sciences Humaines, 2014, pp. 100-101. ↩︎
-
Pour le fonctionnement du Perceptron, cf. Yann Le Cun, Quand la machine apprend, Odile Jacob, 2023, (chap. 3. Machines apprenantes simples). Et Melanie Mitchell, ouvrage cité, « Chapitre 1. Les racines de l’intelligence artificielle » (notamment les sections très pédagogiques : « L’IA sub-symbolique : les perceptrons », « Les entrées de notre perceptron », « L’apprentissage des poids et du seuil du perceptron » et « Les limites des perceptrons »). ↩︎
-
Comme le résume Yann Le Cun (ouvrage cité, conclusion du chapitre 3) : « Le perceptron inaugure l’apprentissage automatique dit supervisé. Dans la machine, la procédure d’apprentissage ajuste les paramètres de manière que la sortie se rapproche de celle que l’on souhaite. Une fois entraînée, une machine bien construite peut aussi reconnaître des exemples qu’elle n’a jamais vus : c’est la propriété de généralisation ». ↩︎
-
A. Newell et H. A. Simon, « GPS : A Program That Simulates Human Thought », P-2257, Rand Corporation, Santa Monica (CA), 1961. Cf. Melanie Mitchell, ouvrage cité, section « L’IA symbolique » dans le « Chapitre 1. Les racines de l’intelligence artificielle ». ↩︎
-
Claude Shannon : « I confidently expect that within a matter of 10 or 15 years, something will emerge from the laboratory which is not too far from the robot of science fiction fame » (1961). Source The Shannon Centennial : 1100100 years of bits. ↩︎
-
Dans sa conférence M. Mitchell indique 1965 comme date de cette citation une conférence 1965. Das son livre elle renvoie au livre d’Herbert Simon de 1965 : The Shape of Automation for Men and Management. Il semblerait que le livre de 1965 reproduise en fait le chapitre d’un livre précédent de d’Herbet Simmon publié en 1960 : The New Science of Management Decision (Cf. Quote Investigator). ↩︎
-
Herbert Simon : « Technologically, as I have argued earlier, machines will be capable, within twenty years, of doing any work that a man can do. Economically, men will retain their greatest comparative advantage in jobs that require flexible manipulation of those parts of the environment that are relatively rough—some forms of manual work, control of some kinds of machinery (e.g., operating earth-moving equipment), some kinds of nonprogrammed problem solving, and some kinds of service activities where face-to-face human interaction is of the essence.” Herbet Simon, The New Science of Management Decision, 1960 ; cf. Quote investigator. ↩︎
-
Cité par Melanie Mitchell aussi dans son livre (page 19), qui donne pour référence : (M. L. Minsky, Computation : Finite and Infinite Machines, Upper Saddle River (NJ), Prentice-Hall, 1967, p. 2). ↩︎
-
Melanie Mitchell, , Intelligence artificielle. Triomphes et déceptions, 2021, Dunod, page 25. ↩︎
-
Pour parler de l’IA « sub-symbolique », Daniel Andler utilise les termes de « neurocalcul » et de « modèle connexionniste ». Pour bien comprendre la différence entre l’IA « symbolique » et l’approche connexionniste, ses enjeux scientifiques et philosophiques, on lira avec profit aux deux chapitres de son (Intelligence artificielle, intelligence humaine : la double énigme, Gallimard, « NRF essais », 2023) : le chapitre 3 « L’ère classique » consacré à l’IA symbolique (dite « IA classique ») et au chapitre 4 « L’âge du connexionnisme » consacré au « neurocalcul » (IA sub-symbolique des réseaux de neurones formels). ↩︎
-
C’est dans 1969 que Seymour Papert et Marvin Minsky publie Perceptrons : An Introduction to Computational Geometry dans lequel ils montrent les limites du perceptron dont certaines sont rédhibitoires même dans la version plus sophistiquée (à plusieurs « couches ») qu’ils jugent tout aussi stérile. C’était pourtant une bonne piste… mais il fallait penser à ajouter une ou plusieurs dizaines de couches de neurones et non pas seulement une ou deux. ↩︎
-
C’est d’ailleurs ce qui arrivera. Cf. McDermott D., M. M. Waldrop, B. Chandrasekaran, J. McDermott, and R. Schank. The dark ages of AI: A panel discussion at AAAI-84. AI Magazine, 6(3):122–134, 1985. ↩︎
-
Dans un article très éclairant, Why AI is Harder Than We Think (2021), Melanie Mitchell explore les raisons du cycle répétitif décrit par Drew McDermott. Sa thèse est que l’excès d’optimisme du public, des médias et même des experts découlent de la façon de parler de l’IA et de nos représentations spontanées sur la nature de l’intelligence. Elle analyse point par point 4 grandes erreurs : 1 Erreur : L’intelligence au sens faible ou étroit se trouve sur un continuum avec l’intelligence générale [il y a en réalité un abîme entre elles] ; 2 Sophisme : Les choses faciles sont faciles et les choses difficiles sont difficiles [c’est le contraire, en IA les choses réputées difficiles (vaincre le champion du monde d’échecs) sont souvent faciles et les choses faciles (donner à une IA les compétences d’un enfant d’un an en matière de perception) extrêmement difficiles] ; 3 Sophisme : L’attrait des mnémoniques magiques. Les mnémoniques désignent en informatique des noms donné à des programmes ou instructions (« COMPRENDRE », « OBJECTIF ») [ce sont des termes anthropomorphiques donc trompeurs qui servent de raccourcis pour désigner des opérations comme lorsqu’on dit que ChatGPT « comprend » ou « lit » un texte] ; 4 Sophisme : L’intelligence est entièrement dans le cerveau [contre quoi nombre de chercheurs affirment que la cognition est incarnée : par exemple que les capacités d’un enfant de moins de deux ans à comprendre intuitivement la permanence de l’objet (ou l’inertie) repose sur son corps et ses perceptions sensorielles]. ↩︎